Google Apps Script로 네이버 뉴스를 채팅방으로 전송하는 서버리스 뉴스봇 만들기
최근에 네이버 뉴스 RSS를 대신할 실시간 뉴스 모니터링 도구를 만들었다. 이번 글에서는 Google Apps Script로 서버리스 뉴스봇인 "Naver News Fetching Bot"을 개발하게 된 계기와 구체적인 구현 방법, 그리고 개발 과정에서 겪은 이슈들과 해결 방법을 상세히 소개한다.

시작은 단순했다. 어느날, 회사에서 일하던 애인이 물었다.
"회사용 채팅방에서 회사명이 포함된 뉴스를 실시간으로 받아볼 수 있을까?"
"네이버 뉴스 RSS가 끊겼는데, 네이버 접속 없이 뉴스를 받을 다른 방법은 없을까?"
해본 적 없는 일이더라도 해낼 수 있어 보인다면 일단 시작해보는 편이다. 오래 전 컨설팅 회사에서 일하던 시절부터 꼭 만들고 싶었던 도구이기도 했다. 하물며 사랑하는 사람이 필요하다니까. 그래서 "Naver News Fetching Bot"을 만들게 되었다.

"Naver News Fetching Bot"은 원하는 검색어가 포함된 최신 네이버 뉴스를 슬랙(Slack), 팀즈(Microsoft Teams), 잔디(Jandi) 또는 구글챗(Google Chat)으로 전송하는 Google Apps Script 기반 서버리스 뉴스봇이다. 처음에는 RSS 데이터를 구글챗으로 넘기는 단순한 형태로 만들었지만, 올해 3월에 네이버 오픈 API 기반으로 코드를 재구축한 뒤 슬랙, 팀즈, 잔디 지원을 차례로 추가했다.
이 글에서는 "Naver News Fetching Bot"의 개발 과정에서 고려했던 사항들, 그리고 구현 방법을 코드와 함께 소개한다. 개발 과정에서 마주했던 몇 가지 이슈와 이를 해결한 방법도 함께 공유한다.
개발 과정에 고려한 사항들
무엇을 위한 도구인가?
이 뉴스봇은 실시간 뉴스 모니터링이 필요한 PR 및 마케팅 실무를 위해 만들었다. 기업이나 브랜드 또는 제품의 평판을 관리하는 일, 시장 동향을 살피는 일, 비즈니스 측면의 위험 요소를 빠르게 탐지하고 대응하는 일의 첫 단계가 뉴스 모니터링이다.
그동안 공공/민간 뉴스 모니터링 업무는 대체로 네이버의 뉴스 RSS 데이터에 의존해왔다. 슬랙(Slack)이나 잔디(Jandi) 등에 RSS 주소만 더하면 원하는 뉴스를 받아볼 수 있었다. 그러나 2022년 3월에 네이버 뉴스 RSS 서비스가 완전히 중단되면서 이것이 불가능해졌다. 구글 뉴스는 매체 수가 너무 적어서 놓치는 뉴스가 많고, 네이버에서 매번 뉴스를 검색하는건 비효율적이다. 시시때때로 크롤링을 하는 방법은 효용 대비 과도한 작업으로 느껴진다.
이 문제를 해결하려고 한 것이 "Naver News Fetching Bot"이다. Google Apps Script의 자체 트리거 기능을 이용해서 원하는 주기마다 네이버 오픈 API로부터 최신 뉴스를 가져와 Webhook을 통해 공용 채팅방에 즉시 공유시킨다. 간단하고 효율적이다.
왜 Google Apps Script인가?
처음에는 AWS Lambda나 Google Cloud Run 같은 클라우드 기반 FaaS 사용을 고려했었다. 그러나 이 뉴스봇을 실제 이용하시게 될 분들의 업무 환경을 고민한 끝에 Google Apps Script로 전환했다.
업의 경계가 점차 사라져가는 추세이긴 하지만, 비개발 직군에 종사하시는 많은 분들에게 클라우드, 서버리스 등의 개념은 여전히 생소하고 어려운 편이다. 업무 도입에 필요한 과정들(계정 생성, 권한 관리, 결제 관리 등) 역시 복잡하다. 개발자 입장에선 극히 간단한 프로그램이더라도 도입하는 입장에선 높은 진입장벽을 느낄 수 있다. 그 장벽을 낮추고 싶었다.
Google Apps Script는 아래와 같은 장점이 있다.
- 접근성이 좋다. 구글 아이디만 있으면 누구나 바로 시작할 수 있다. 많은 회사에서 업무 플랫폼으로 이용되는 Google Workspace와도 잘 연동된다.
- 사용이 간편하다. 웹 환경에서 바로 IDE를 쓸 수 있고, 이벤트 트리거 설정과 로그 조회가 간편하다. 사용 언어가 JavaScript 기반인 것도 장점이다.
- 무료다. 세상의 수많은 편리한 솔루션들이 단지 비용에 대한 저항감 때문에 도입되지 못하는 경우를 많이 보고 겪어왔다. 개별 실무자가 부담 없이 테스트하고 도입할 수 있는 환경으로서 Google Apps Script는 강력한 이점을 가진다.
왜 Incoming Webhook인가?
외부로부터 협업용 채팅 솔루션으로 데이터를 전송하는 가장 간단한 방법이 Incoming Webhook(수신 웹후크)다. 특정 채팅방에 설정된 Webhook용 URL에 JSON 데이터를 포함한 HTTP POST 요청을 보내면 되는 방식이다.
현재 여러 협업 도구들에서 Incoming Webhook 기능을 지원한다. 각 도구 별로 공식 지원되는 JSON 구조에 맞춰 데이터 항목을 구성한 뒤 fetch 시키기만 하면 된다. 따라서 코드의 유지 보수가 간편하고, 확장성도 좋다.
세부 구현 방법
v2.2.2 버전에서 각 구현부의 핵심 부분을 발췌해서 소개합니다. 업데이트 과정에서 이전과 달라진 부분이 많아, 아래 내용을 새로 수정하고 다듬었습니다. 최신 코드는 저의 깃허브 리포지터리에서 확인하실 수 있습니다.- 업데이트 날짜 : 2022년 8월 25일
1. 전역 설정값 설정부
뉴스봇 구동에 쓰이는 주요 설정값들을 globalVariables()로 묶어서, 필요할 때마다 객체로 불러내어 쓸 수 있도록 했다. 사용자 입장에선 전체 코드 가운데 이 부분만 수정하면 되도록 배려했다.
function globalVariables() {
return values = {
// 디버그 모드 설정
DEBUG : false,
// 네이버 검색 오픈 API Client ID 및 Secret 값
clientId : "[네이버 오픈 API용 Client ID]",
clientSecret : "[네이버 오픈 API용 Client Secret]",
// 네이버 뉴스 검색어
keyword : "[검색키워드]",
// Slack 전송 설정
allowBotSlack : false,
webhookSlack : "[URL]",
// Microsoft Teams 전송 설정
allowBotTeams : false,
webhookTeams : "[URL]",
// JANDI 전송 설정
allowBotJandi : false,
webhookJandi : "[URL]",
// Google Chat Space 전송 설정
allowBotGoogle : false,
webhookGoogle : "[URL]",
// Google Spreadsheet 아카이빙 설정
allowArchiving : false,
spreadsheetId : "[SPREADSHEET_ID]",
sheetName : "[SPREADSHEET_SHEET_NAME]",
sheetTargetCell : "[SPREADSHEET_SHEET_NAME]!A2"
};
}
2. 네이버 오픈 API 호출 및 뉴스봇 구동부
Google Apps Script의 트리거 기능으로 실제 실행하게 될 구동부가 위치한 runFetchingBot() 부분이다. 이곳에서 처리되는 프로세스를 간략하게 요약하면 다음과 같다.
- 뉴스봇 구동에 필요한 설정값들의 유무를 검증한다.
- 뉴스봇의 최초 구동 여부를 판별한다.
- 뉴스봇에 지정된 검색 키워드의 변화 유무를 판별한다.
globalVariables()에 저장된 설정값대로 네이버 뉴스 피드를 가져온다.- 피드의 응답 코드가 정상(
200)이라면 뉴스 데이터 처리를 시작한다.
우선 뉴스봇이 구동되기 위해 필요한 설정값들을 체크한 뒤, 뉴스봇의 최초 구동 여부와 기존에 지정된 검색 키워드의 변화 유무를 판별한다.
function runFetchingBot() {
// 뉴스봇 구동 설정값들을 불러온다.
const g = globalVariables();
...
// PropertiesService 객체에 저장된 lastArticleUpdateTime, registeredKeyword 속성값이 있는지 체크한다.
const lastArticleUpdateTime = getProperty("lastArticleUpdateTime") ? new Date(parseFloat(getProperty("lastArticleUpdateTime"))) : null;
const registeredKeyword = getProperty("registeredKeyword") ? getProperty("registeredKeyword") : null;
...
네이버의 뉴스 검색 API에서는 출력 결과 건수를 10에서 100 사이로만 지정할 수 있다. 최신 뉴스만 중복 없이 전송받으려면 마지막 뉴스 항목의 전송 시점을 기준으로 이후 시각에 올라온 뉴스만 처리하도록 해야 하는데,** 해당 시점을 알 수 없는 최초 실행** 시에는 지정된 수 만큼의 뉴스들이 채팅방에 우다다 올라오게 된다. 받아보는 입장에선 갑작스러운 알림 폭탄에 놀랄 수 있다. 그래서 첫 실행 시점을 체크하는 프로세스를 추가했다.
v2.2.1까지는 최초 실행 시점만 기억시키고 다음 번 실행때부터 뉴스 전송이 시작되도록 했었다. 그러나 실제 사용해보니, 이런 방식은 사용자가 뉴스봇의 정상 설치 여부를 바로 직관적으로 확인하기 어렵다는 단점이 있었다. 따라서 v2.2.2부터는 연동된 메신저에 "설치 완료" 메시지와 최신 뉴스 1건을 샘플로 함께 전송하도록 변경했다.
아울러 뉴스봇을 이용하던 도중 검색 키워드를 변경했을 경우, 변경 내역을 확인하여 "키워드 변경 완료" 메시지를 별도로 전송하는 기능도 함께 추가했다. 위의 registeredKeyword 변수는 이를 위해 새로 추가한 것이다.
마지막 뉴스 항목의 최종 전송 시점, 그리고 기존에 설정된 검색 키워드를 기억하는 용도로는 PropertiesService 클래스를 이용했다. 이 클래스는 일회성 수명 주기를 가진 스크립트를 위해 키와 값의 쌍을 별도로 저장할 수 있게 해준다. 이에 대해서는 아래 "개발 과정에서 겪었던 이슈들" 파트에서 좀 더 자세히 소개하기로 한다.
다음으로 소개할 파트는 네이버 뉴스 피드를 실제 가져오는 부분이다.
...
// lastArticleUpdateTime 속성값의 유무로 뉴스봇 최초 실행 여부를 판단하고 뉴스 피드를 받아온다.
if (!lastArticleUpdateTime) {
feed = getFeed(g.keyword, g.clientId, g.clientSecret, true);
Logger.log("* 뉴스봇 초기 설정을 시작합니다.\n");
}
else {
feed = getFeed(g.keyword, g.clientId, g.clientSecret);
}
// 네이버 뉴스 피드를 체크하고, 피드의 응답 코드가 정상(200)이라면 뉴스봇 기능을 구동한다.
if (feed.getResponseCode() == 200) {
// 최초 실행한 경우 registeredKeyword 속성값을 등록한 뒤 안내 메시지를 전송한다.
if (!lastArticleUpdateTime) {
Logger.log("* 네이버뉴스 검색 키워드 등록 : '" + g.keyword + "'\n");
setProperty("registeredKeyword", g.keyword);
Logger.log("* 등록된 검색 키워드로 최근 1개 뉴스를 샘플로 전송하여 드립니다.\n");
postMessage(g, welcomeMessage(g.keyword));
}
else {
// 만약 기존에 등록된 키워드와 다른 검색 키워드로 변경되었다면, 변경된 키워드를 registeredKeyword 속성값으로 저장하고 안내 메시지를 전송한다.
if (registeredKeyword != g.keyword) {
Logger.log("* 네이버뉴스 검색 키워드 변경 : '" + registeredKeyword + "' -> '"+ g.keyword + "'\n");
postMessage(g, changeKeywordMessage(registeredKeyword, g.keyword));
setProperty("registeredKeyword", g.keyword);
}
Logger.log("* 마지막 뉴스 전송 시점 : " + lastArticleUpdateTime);
Logger.log("* 네이버뉴스 키워드 검색 시작 : '" + g.keyword + "'");
}
getArticle(g, feed, lastArticleUpdateTime);
}
// 200 이외의 응답 코드가 리턴될 경우 에러 체크를 위한 헤더 및 내용을 로그로 출력시킨다.
else {
Logger.log("* 뉴스를 가져오는 과정에서 에러가 발생했습니다. 로그를 참고해주세요.\n");
Logger.log(feed.getHeaders());
Logger.log(feed.getContentText());
return;
}
}조금 길지만 내용은 간단하다. 앞서 체크했던 최초 구동 여부를 기준으로 조건에 맞는 뉴스 피드를 getFeed() 함수로 받아온다. 받아온 피드의 응답 코드가 정상(200)이면 다음 프로세스에 해당하는 getArticle()을 실행하고, 그렇지 않으면 에러 코드를 로그에 남긴 뒤 종료한다. setProperty()는 앞서 소개한 PropertiesService 클래스에 지정된 속성값을 저장시키며, postMessage()는 메신저 앱에 원하는 문구를 메시지로 전송시키는 역할을 한다.
여기서 뉴스 피드를 받아오는 getFeed() 함수는 아래와 같이 작성했다.
function getFeed(keyword, clientId, clientSecret, startup=false) {
const feedUrl = getFeedUrl(keyword, startup);
const options = {
"method": "get",
"headers": {
"X-Naver-Client-Id": clientId,
"X-Naver-Client-Secret": clientSecret
}
};
return UrlFetchApp.fetch(feedUrl, options);
}Google Apps Script에서는 HTTP request에 대해 UrlFetchApp이라는 객체로 결과값을 받아올 수 있다. 이 객체의 .fetch() 메서드로 URL에 요청을 보낼 수 있고, .getResponseCode() 메서드로 응답 코드를 확인할 수 있다.
3. 뉴스 데이터 처리부
네이버 오픈 API로 받아온 최신 뉴스 데이터에서 $.channel.item[*] 항목들을 골라낸다. 이때 받아온 데이터는 시간 역순으로 되어 있으므로, 가장 최근에 올라온 뉴스가 마지막에 처리될 수 있도록 .reverse() 메서드로 시간순 정렬을 시켜주었다.
function getArticle(g, feed) {
// 뉴스 검색 결과물을 가져와 item 단위로 시간순 정렬시키고 Fetching 작업을 시작한다.
const xml = XmlService.parse(feed.getContentText());
const items = xml.getRootElement().getChild('channel').getChildren('item').reverse();
...네이버 검색 API에서는 시간/분/초 단위의 범위 지정이 불가능하다. 따라서 일단 받아온 뉴스 항목들 가운데 마지막 뉴스 업데이트 시점(lastArticleUpdateTime)보다 이후에 올라온 뉴스들만 처리되도록 구성했다. 그리고 각 항목마다 존재하는 데이터 필드들을 뉴스 제목(title), URL(link), 매체명(source), 발췌문(description), 게재 시각(pubDateText)으로 구분하여 postArticle()와 archiveArticle() 함수로 넘기도록 했다.
...
let cnt = 0;
let archiveItems = [];
for (let i = 0; i < items.length; i++) {
const pubDate = new Date(items[i].getChildText('pubDate'));
if (!lastArticleUpdateTime || pubDate > lastArticleUpdateTime) {
// 각 item 별로 데이터 필드들을 가져온다.
const title = bleachText(items[i].getChildText('title'));
const link = items[i].getChildText('link');
const source = getSource(items[i].getChildText('originallink'));
const description = bleachText(items[i].getChildText('description'));
const pubDateText = Utilities.formatDate(pubDate, "GMT+9", "yyyy-MM-dd HH:mm:ss");
// DEBUG 모드일 경우 => 챗봇/아카이빙 기능을 정지하고 처리된 데이터를 로그로만 출력시킨다.
if (g.DEBUG) {
Logger.log("----- " + items.length + "개 항목 중 " + (i + 1) + "번째 -----");
Logger.log(pubDateText + "\n" + title + "\n" + source + "\n" + link + "\n" + description);
}
// DEBUG 모드가 아닐 경우 => 챗봇/아카이빙 기능을 실행한다.
else {
Logger.log("'" + title + "' 항목 게시 중...");
if (g.allowBotSlack || g.allowBotTeams || g.allowBotJandi || g.allowBotGoogle) {
postArticle(g, pubDateText, title, source, description, link);
}
if (g.allowArchiving) {
archiveItems[archiveItems.length] = [pubDateText, title, source, link, description];
}
}
// PropertiesService 객체에 마지막 뉴스 업데이트 시점을 새로 업데이트한다.
setProperty("lastArticleUpdateTime", pubDate.getTime());
cnt++;
}
}
Logger.log("* 총 " + parseInt(cnt, 10) + "건의 항목이 게시되었습니다.");
// DEBUG 모드가 아니며 뉴스 항목의 구글 시트 저장이 설정되었다면, 새로 Fetching된 항목들을 시트에 전송한다.
if (!g.DEBUG && g.allowArchiving && cnt > 0) {
archiveArticle(g.spreadsheetId, g.sheetName, g.sheetTargetCell, archiveItems);
}
}특정 키워드에 대한 뉴스 검색 결과를 네이버 오픈 API로 받아올 경우, 뉴스 제목(title)과 발췌문(description) 필드에 해당 키워드를 강조하는 HTML 태그가 추가된 채로 데이터가 넘어온다. 경우에 따라 일부 특수문자가 HTML 엔티티 문자로 변환되어 잘못 들어오기도 한다. 따라서 이걸 없애기 위한 bleachText() 함수를 아래와 같이 추가했다.
function bleachText(text) {
// 데이터 필드에 포함된 HTML Tag를 제거하고 Entity들을 원래 의도된 특수문자로 대체한다.
text = text.replace(/(<([^>]+)>)/gi, '');
text = text.replace(/"/gi, '"');
text = text.replace(/'/gi, "'");
text = text.replace(/</gi, '<');
text = text.replace(/>/gi, '>');
text = text.replace(/&/gi, '&');
text = text.replace(/`/gi, "'");
text = text.replace(/'/gi, "'");
return text;
}다만 매체명(source)의 경우, 2022년 8월 현재까지도 네이버 오픈 API에서 지원하지 않고 있다. 뉴스 모니터링 업무에서 매체명은 중요도가 높은 정보이므로 이 문제를 해결할 방안이 필요했다. 이에 대해서는 아래 "개발 과정에서 겪었던 이슈들" 파트에서 다시 소개하겠다.
4. 뉴스 전송부
받아온 데이터의 처리가 끝났으니, 이제 전송할 일만 남았다. 앞서 살펴봤던 UrlFetchApp 객체의 .fetch() 메서드로 원하는 채팅방의 Incoming Webhook URL에 POST 요청을 전송시킨다. 이때 각 협업 솔루션 별로 지정된 payload 양식에 따라 게시물의 레이아웃을 정할 수 있는데, 이에 대해서는 각 솔루션별 안내 문서를 참고하기 바란다.
async function postArticle(g, pubDateText, title, source, description, link) {
// 채팅 서비스별 초당/분당 request 횟수 제한을 고려하여 sleep 기능을 정의한다.
// Source : https://stackoverflow.com/a/39914235
const sleep = ms => new Promise(resolve => setTimeout(resolve, ms));
if (g.allowBotSlack) {
const article = createArticleCardSlack(pubDateText, title, source, description, link);
const params = {
"method": "post",
"contentType": "application/json",
"payload": JSON.stringify(article)
};
UrlFetchApp.fetch(g.webhookSlack, params);
}
...
// 채팅 솔루션별 초당/분당 request 횟수 제한을 고려하여 다음 항목 처리 전에 일정 시간 대기시킨다.
await sleep(200);
}
Google Apps Script는 Spreadsheet와 긴밀히 연동되는데, 이걸 가능하게 하는 객체가 SpreadsheetApp다. 이를 이용하여 Google Spreadsheet로의 아카이빙 기능을 아래와 같이 구현했다.
function archiveArticle(spreadsheetId, sheetName, sheetTargetCell, archiveItems) {
const ss = SpreadsheetApp.openById(spreadsheetId);
// sheetName으로 지정된 시트가 없을 경우, header를 포함하여 새로 생성한다.
if (!ss.getSheetByName(sheetName)) {
ss.insertSheet(sheetName, 1);
const headerRange = Sheets.newValueRange();
headerRange.values = [["날짜/시각", "제목", "매체명", "URL", "내용"]];
const headerTargetCell = sheetName + "!A1";
Sheets.Spreadsheets.Values.update(headerRange, spreadsheetId, headerTargetCell, {
valueInputOption: 'RAW'
});
}
const ws = ss.getSheetByName(sheetName);
ws.insertRowsBefore(2, archiveItems.length);
const valueRange = Sheets.newValueRange();
valueRange.values = archiveItems.reverse();
Sheets.Spreadsheets.Values.update(valueRange, spreadsheetId, sheetTargetCell, {
valueInputOption: 'USER_ENTERED'
});
}
개발 과정에서 겪었던 이슈들
1. 마지막 뉴스 업데이트 시점의 저장 문제
Google Apps Scripts는 이벤트에 따라 주어진 스크립트를 일회성으로 실행시킨다. 트리거 또는 실행 명령에 따라 실행 환경이 새로 시작되고, 종료와 함께 수명이 끝난다. AWS Lambda처럼 실행 환경에 대한 임시 캐시를 제공하지도 않는다. 그렇다면, 어떻게 마지막 뉴스 업데이트 시점을 기억시켜서 이전에 전송된 적 없는 최신 뉴스만 받아보게 할 수 있을까? 공식 문서를 찾다가 발견한 PropertiesService 클래스가 이에 대한 해답을 주었다.
PropertiesService는 Google Apps Script 환경에서 스크립트를 위한 임의의 키-값 쌍을 저장할 수 있는 클래스다. 이 클래스는 권한 범위에 따라 세 종류로 구분된 메서드들을 통해 Properties 객체로 접근하도록 해준다. 여기서는 오직 이 뉴스봇 스크립트를 통해서만 접근 가능하도록 .getScriptProperties() 메서드를 이용했고, 이를 통해 매 실행때마다 마지막 뉴스 업데이트 시점의 timestamp를 기록시키는 방법으로 문제를 해결했다.
2. PropertiesService 클래스에 timestamp를 저장할 때의 문제
PropertiesService에 저장되는 키-값 쌍은 모두 string 타입으로 고정된다. 그래서 "뉴스 데이터 처리부"에서 PropertiesService로부터 마지막 뉴스 업데이트 시점을 가져올 때 .parseInt() 메서드를 쓰면 될 것으로 예상했다. 그런데 실행 테스트 과정에서 문제가 생겼다. 매번 똑같은 양의 뉴스 데이터가 중복 체크 없이 계속 넘어왔다.
로그를 찾아보니 PropertiesService에서 가져와 정수로 변환 시킨 timestamp의 값이 1로 찍히고 있었다. 이상하다 싶어 해당 값을 변환 처리 없이 직접 가져와 보니 그 결과는 아래 이미지와 같았다.

timestamp 대신 지수 형태의 string이 리턴되었다.JavaScript와 Google Apps Script에서는 숫자를 number 타입으로 인식하여 메모리에 IEEE-754 규격을 따르는 부동소수점 포맷으로 저장한다는 사실을 이번에 알게 됐다. 콘솔에서 볼 때엔 2진법을 거쳐 10진법으로 변환된 결과를 보게 되지만, 메모리 상에서는 그렇지 않았던 것이다. 이렇게 저장된 timestamp가 PropertiesService 클래스에 지수 표기법 형태의 string 타입으로 입력되고, 이것이 parseInt() 메서드를 거치면서 소수점 이하 값들이 버려진 채 위와 같은 결과가 나오게 된 것이다.
이 문제는 .parseInt() 대신 .parseFloat()를 써서 해결했다. 이 메서드는 지수(e 또는 E) 문자가 포함된 지수형 문자열을 실수로 바꿔주는 역할도 한다. 이렇게 변환한 timestamp 값으로 원래 얻고자 했던 Date 객체를 다시 정상적으로 얻을 수 있었다.

parseFloat()를 쓰니 timestamp 문제가 해결되었다.3. 네이버 측의 매체명 데이터 필드 미지원
매체명 역시 뉴스 모니터링에 필요한 정보지만, 네이버의 API 규격에는 의아하게도 이것이 제외되어 있다. 다만 뉴스의 원문 URL을 담은 데이터 필드(originallink)는 존재했다. 그래서, 다소 수고스러운 방식이지만 원문 URL에 포함된 도메인 주소를 기준으로 매체명을 판별하기로 했다.
매체명 판별에 필요한 데이터는 별도의 크롤링 작업을 통해 얻었다. 이 작업에는 정치, 경제, 국제, 문화, 스포츠, 지역(서울, 경기, 강원, 충북, 충남, 전북, 전남, 경북, 경남, 제주 등) 등 6개 카테고리에 걸쳐 약 8만 건의 뉴스를 가져와 736개의 매체명과 도메인을 뽑아내는 과정이 포함되었다. 이렇게 뽑아낸 데이터는 엑셀로 1차 전처리를 한 뒤, ["도메인", "매체명"] 형태의 배열을 원소로 갖는 이중 배열 형태로 정리하여 listSource() 안에 넣었다. 그 결과물은 여기서 볼 수 있다.
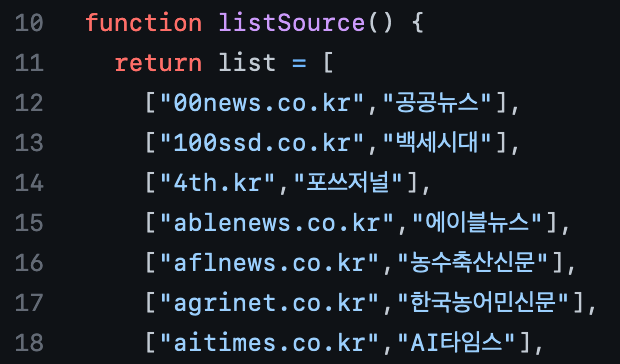
매체명을 판별할 코드는 아래와 같이 작성했다. 예전에는 위의 데이터에 포함되지 못한 매체를 (알수없음)으로 표기했지만, 2022년 8월부터는 이런 경우엔 원문이 실린 1차 도메인 주소를 정규식으로 뽑아내어 대신 표기하도록 바꾸었다. 회사 업무에 뉴스봇을 사용 중이신 한 마케터님의 의견 덕분에 개선할 수 있었던 부분이다. 아이디어를 주신 그분께 이 자리를 빌어 감사드린다.
function getSource(originallink) {
// source.gs에 저장된 언론사별 URL 리스트를 가져온다.
const list = listSource();
// 넘겨받은 뉴스 원문 주소에서 불필요한 부분을 제거한다.
const address = originallink.toLowerCase().replace(/^(https?:\/?\/?)?(\/?\/?www\.)?(\/?\/?news\.)?(\/?\/?view\.)?(\/?\/?post\.)?(\/?\/?photo\.)?(\/?\/?photos\.)?(\/?\/?blog\.)?/, "");
const domain = address.match(/^([^:\/\n\?\=]+)/)[0];
// 원문 주소에 맞는 매체명을 탐색하여 리턴한다. 탐색 결과가 없을 경우 원문이 실린 도메인 주소를 리턴한다.
const index = searchSourceIndex(address, list);
if (index >= 0 && index <= list.length - 1) {
return list[index][1];
}
else if (domain) {
return domain;
}
else {
return "(알수없음)";
}
}이제 이중 배열 형태의 매체명 데이터에서 원문 주소에 맞는 매체명을 탐색하는 작업이 남았다. 코드를 처음 공개할 당시엔 가장 구현하기 쉬운 순차 탐색을 이용했다. 그러나 매체명 데이터를 정렬 상태로 넣을 수 있다는 점에 착안하여, 2022년 5월에 더 나은 연산 효율을 가진 이진 탐색으로 바꾸었다. 이렇게 변경한 코드는 다음과 같다.
function searchSourceIndex(address, list) {
let left = 0;
let right = list.length - 1;
while (left <= right) {
let index = Math.floor((left + right) / 2);
let address_stripped = address.substr(0, list[index][0].length);
if (address_stripped === list[index][0]) {
return checkSourceIndex(index, list, address, address_stripped);
}
else if (address_stripped < list[index][0]) {
right = index - 1;
}
else {
left = index + 1;
}
}
return -1;
}
다만 이진 탐색의 경우 중복 데이터 구간 처리에 약점이 있다. 포브스코리아(jmagazine.joins.com/forbes)나 월간중앙(jmagazine.joins.com/monthly)처럼 같은 (서브)도메인을 공유하는 서로 다른 매체들을 판별할 때 문제가 생길 수 있는 것이다.
이 문제는 고민 끝에, 1차 탐색 결과로 얻은 index 이후 번째의 매체사 경로 정보가 원문 주소에 포함되어 있는지 체크하는 단계를 추가하여 해결했다.
function checkSourceIndex(index, list, address, address_stripped) {
let i = index;
// addressSearch()에서 확인된 매체명 경로를 포함하는 하위 경로가 추가로 존재하는지 체크한다.
while (i + 1 <= list.length - 1) {
if (list[i + 1][0].includes(address_stripped)) {
i++;
}
else {
break;
}
}
// 추가 하위 경로가 없다면 원래의 매체명 index값을 리턴한다.
if (i === index) {
return index;
}
// 만약 있다면, 해당되는 범위의 우측 끝에 위치한 매체명부터 차례로 체크한 뒤 조건에 맞는 매체명 index값을 리턴한다.
while (i >= index) {
if (address.includes(list[i][0])) {
return i;
}
i--;
}
return -1;
}
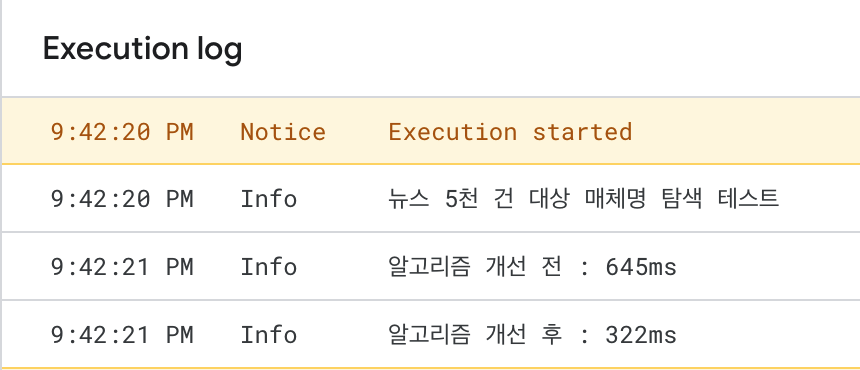
이렇게 해서 알고리즘을 개선한 결과, 전체적인 탐색 시간 효율이 크게 향상된 것을 확인할 수 있었다. 연산 시간도 과금 기준 중 하나인 클라우드 환경에서는 이런 작은 변화가 큰 차이를 만들 수 있을 것이다.
맺음말
특정 플랫폼에서 일회성으로 실행되는 짧은 코드일 지언정, 초보자로서 문제의 해결 방법을 직접 구상하고 풀어나가는 과정이 녹록하지는 않았다. 다행히 하버드 CS50x에서 한 주 남짓 배웠던 JavaScript 기초를 되짚으면서 문제를 해결할 수 있었다. 덕분에 FaaS 환경에 맞는 애플리케이션 구현에도 관심이 생겼다. 더 큰 성장을 위한 작은 경험을 얻었으니 만족한다.
지난 3월에 슬랙 지원 기능을 추가하는 과정에서 한 이용자 분으로부터 뜻밖의 감사 메일을 받았다. 한 사람을 위해 만든 도구가 다른 분들께도 도움이 될 수 있음을 실감했다. 그 기억이 이 글을 쓰는 계기가 되었다. 네이버 뉴스 RSS의 대체재가 필요하신 분들, Google Apps Script를 이용한 채팅 솔루션 연동이나 업무 자동화가 필요하신 분들께 도움이 되길 기원한다.