Docker Swarm의 주요 용어, 활성화 방법 및 노드(Node) 관리법 살펴보기
이번 글에서는 도커 스웜(Docker Swarm)의 주요 용어와 시작 방법을 입문자의 관점에서 간략히 소개한다. 여러 대의 호스트를 이용하여 다중 노드 클러스터를 구축하고, 여기에 포함된 노드들을 관리하는 데에 필요한 방법도 함께 안내한다.
개요
도커(Docker)는 단일 호스트 안에서 컨테이너 기반 애플리케이션을 관리할 때 유용한 도구다. 하지만 단일 호스트로 구성된 환경은 확장성(Scalability)과 가용성(Availabilty), 그리고 장애 허용성(Fault Tolerance) 측면에서 많은 한계점을 가진다. 만약 애플리케이션 이용자가 늘어나면서 호스트의 가용 시스템 자원이 바닥나게 된다면? 혹은 어떠한 이유로든 호스트가 일시적으로 작동 불능의 상태가 된다면? 아마도 애플리케이션의 서비스가 곧바로 중단되는 상황을 맞이하게 될 것이다. 따라서, 개인 블로그 정도의 작은 규모가 아닌 이상, 대개의 경우에는 여러 대의 호스트를 함께 운영하며 이러한 상황에 대비하게 된다.
그런데 여러 대의 호스트에서 컨테이너를 관리하려니, 도커(Docker) 자체 만으로는 해결하기 어려운 또다른 문제를 마주하게 된다.
- 서로 다른 각각의 호스트들을 어떻게 연결하고 관리할 것인가?
- 어떤 컨테이너를 어느 호스트에 배치하여 구동시킬 것인가?
- 각기 다른 호스트에 배치된 컨테이너들의 상호 통신을 어떻게 제어할 것인가?
어디서 많이 본 것 같은 문제들이다. 그렇다. 바로 위와 같은 문제들을 해결하기 위해 나타난 것이 "컨테이너화 된 애플리케이션에 대한 자동화된 설정, 관리 및 제어 체계", 즉 컨테이너 오케스트레이션(Container Orchestration)이다. 이전에 "쿠버네티스와 컨테이너 오케스트레이션, 그리고 핵심 설계 사상"이란 글을 통해 살펴봤던 개념이기도 하다.
도커(Docker) 역시 자체적으로 컨테이너 오케스트레이션을 위한 도구를 마련해 두었다. 이번에 소개할 도커 스웜(Docker Swarm)이 그것이다.
지금 시점에 왜 Docker Swarm인가?
현재 도커 스웜(Docker Swarm)은 사실상 유지보수 단계에 접어들었다. 클라우드 컴퓨팅 회사 미란티스(Mirantis)가 2019년 11월에 도커(Docker)의 엔터프라이즈 플랫폼 사업을 인수한 이래로 도커 스웜(Docker Swarm)의 장래성엔 물음표가 가득했다. 이런 여론을 의식한 듯 지난 2022년 2월에 미란티스는 도커 엔진(Docker Engine)에 포함된 스웜킷(SwarmKit) 프로젝트의 관리를 계속 이어나가겠다고 발표했지만, 실질적으로는 더 이상의 큰 변화를 기대하기 어려운 상태다.
쿠버네티스가 컨테이너 오케스트레이션에 관한 사실상의 표준 기술로 자리 잡은 상태에서 도커 스웜(Docker Swarm)은 더 이상 매력적인 선택지가 아닐 수 있다. 그럼에도 불구하고, 인프라 관련 학습자로서 나는 아래의 장점들을 눈여겨보게 되었다.
- 쿠버네티스 만큼은 아니더라도, 여러 대의 호스트로 구성된 중소 규모의 클러스터에서 컨테이너 기반 애플리케이션 구동을 제어하기에 충분한 기능을 갖추고 있다.
- 도커 엔진(Docker Engine)이 설치된 환경이라면 별도의 구축 비용 없이 스웜 모드(Swarm Mode)를 활성화하는 것만으로 시작할 수 있다.
- 도커 컴포즈(Docker Compose)를 사용해 본 사람이라면 도커 스웜(Docker Swarm)의 스택(Stack)을 이용한 애플리케이션 운영에 곧바로 적응할 수 있다.
- 도커 데스크탑(Docker Desktop)으로도 클러스터 관리와 배포가 모두 가능한 단일 노드 클러스터를 바로 만들 수 있다. 따라서 최소한의 자원으로 컨테이너 오케스트레이션 환경을 만들어 시험해볼 수 있다.
이처럼 진입 장벽이 낮고, 간단한 구조로 빠르게 시험 가능한 특성은 학습자의 입장에서 매우 큰 이점이다. 같은 컨테이너 오케스트레이션 도구로서 도커 스웜(Docker Swarm)에 대해 익힌 내용은 추후 쿠버네티스 등 엔터프라이즈 레벨의 도구를 다루는 과정에도 도움이 되리라 생각한다.
주요 용어 정리
입문을 시작하기에 앞서, 도커 스웜에서 흔하게 사용되는 주요 용어들의 개념을 먼저 살펴보자. 아래 용어들을 숙지한다면 이후에 소개할 내용을 이해하는 데에 큰 어려움이 없을 것이다.
- 노드(Node) : 클러스터를 구성하는 개별 도커 서버를 의미한다.
- 매니저 노드(Manager Node) : 클러스터 관리와 컨테이너 오케스트레이션을 담당한다. 쿠버네티스의 마스터 노드(Master Node)와 같은 역할이라고 할 수 있다.
- 워커 노드(Worker Node) : 컨테이너 기반 서비스(Service)들이 실제 구동되는 노드를 의미한다. 쿠버네티스와 다른 점이 있다면, Docker Swarm에서는 매니저 노드(Manager Node)도 기본적으로 워커 노드(Worker Node)의 역할을 같이 수행할 수 있다는 것이다. 물론 스케줄링을 임의로 막는 것도 가능하다.
- 스택(Stack) : 하나 이상의 서비스(Service)로 구성된 다중 컨테이너 애플리케이션 묶음을 의미한다. 도커 컴포즈(Docker Compose)와 유사한 양식의
YAML파일로 스택 배포를 진행한다. - 서비스(Service) : 노드에서 수행하고자 하는 작업들을 정의해놓은 것으로, 클러스터 안에서 구동시킬 컨테이너 묶음을 정의한 객체라고 할 수 있다. 도커 스웜에서의 기본적인 배포 단위로 취급된다. 하나의 서비스는 하나의 이미지를 기반으로 구동되며, 이들 각각이 전체 애플리케이션의 구동에 필요한 개별적인 마이크로서비스(microservice)로 기능한다.
- 태스크(Task) : 클러스터를 통해 서비스를 구동시킬 때, 도커 스웜은 해당 서비스의 요구 사항에 맞춰 실제 마이크로서비스가 동작할 도커 컨테이너를 구성하여 노드에 분배한다. 이것을 태스크(Task)라고 한다. 하나의 서비스는 지정된 복제본(replica) 수에 따라 여러 개의 태스크를 가질 수 있으며, 각각의 태스크에는 하나씩의 컨테이너가 포함된다.
- 스케줄링(Scheduling) : 도커 스웜에서 스케줄링은 서비스 명세에 따라 태스크(컨테이너)를 노드에 분배하는 작업을 의미한다. 2022년 8월 기준으로 도커 스웜에서는 오직 균등 분배(spread) 방식만 지원하고 있다. 물론 노드별 설정 변경 또는 라벨링(labeling)을 통해 스케줄링 가능한 노드의 범위를 제한할 수도 있다.
Docker Swarm 시작하기
여기서는 Ubuntu 22.04가 설치된 AWS의 t2.micro 인스턴스 3개를 이용하여 3개의 노드로 구성된 클러스터를 구축해 볼 것이다. t2.micro 인스턴스는 1개의 vCPU와 1 GiB RAM을 지원한다. 잠깐의 실습 용도로는 충분한 사양이다.
사전 준비 사항
클러스터에 포함시킬 각 호스트에 도커 엔진(Docker Engine) 1.12 버전 이상이 설치되어 있어야 한다. 또한 아래의 포트들이 반드시 사용 가능한 상태여야 한다. AWS에서는 아래 내용이 포함된 보안 그룹(Security Group)을 생성한 뒤 각 호스트에 적용시키면 된다.
2377/tcp: 클러스터 관리에 사용되는 포트다.7946/tcp,7946/udp: 노드 간 통신에 사용된다.4789/udp: 클러스터에서 사용되는 Ingress 오버레이 네트워크 트래픽에 사용된다.
내 경우에는 도커 설치와 더불어 앞으로의 관리상 편의를 위해 각 호스트마다 아래 명령어를 추가로 실행했다.
# 아래 명령어들은 Ubuntu 기준으로 작성되었다.
# 각 호스트를 구분하기 쉽도록 호스트네임을 sjhong-node-## 형식으로 변경한다.
sudo hostnamectl set-hostname <노드명>
# 인스턴스의 기본 사용자 계정(ubuntu)이 sudo 없이 docker 명령을 다룰 수 있도록 조정한다.
sudo usermod -aG docker ubuntu
# 재부팅을 통해 위 변경내용을 호스트에 반영시킨다.
sudo reboot
Docker Swarm 모드 활성화
도커 엔진(Docker Engine) 자체에 도커 스웜(Docker Swarm)이 통합되어 있다. 도커(Docker)가 설치되어 있다면, 아래의 한 줄 명령으로 스웜 모드(Swarm Mode)를 바로 시작할 수 있다.
docker swarm init
이렇게 되면 현재 접속 중인 호스트로 단일 노드로 구성된 클러스터가 새로 구축된다. 만약 특정 IP주소를 기준으로 클러스터를 시작하려면 아래와 같이 입력하면 된다.
docker swarm init --advertise-addr <매니저 노드 IP주소>
도커 스웜(Docker Swarm)에서 노드는 매니저 노드(Manager Node), 워커 노드(Worker Node)로 구분된다. 위의 명령문은 --advertise-addr 플래그로 지정된 주소의 호스트를 새로운 클러스터의 매니저 노드로 지정하여 활성화시킨다.
스웜 모드(Swarm Mode) 활성화가 완료되면 아래와 같은 안내문이 출력된다.
Swarm initialized: current node (9yubq203dgcl82o3n2bb2s31w) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-3h415tip2x8wh4xyv9g3uel3sp6ldrgsayusfvf4ebb8b36bvy-e0ghonmhzr286anttg7eybbd3 172.31.14.44:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
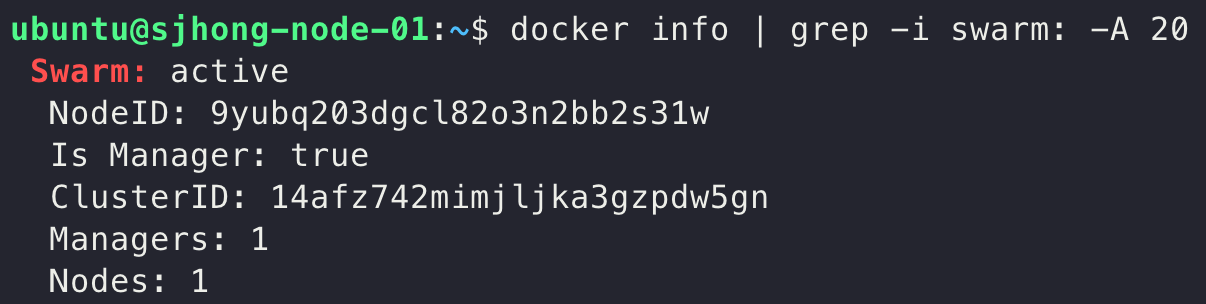
도커 스웜(Docker Swarm)이 잘 활성화 되었는지 확인하고 싶다면 docker info 명령어를 입력해보자. 아래 스크린샷과 같이, Server.Swarm 값이 active로 바뀐 것을 볼 수 있을 것이다.
클러스터 만들기
단일 노드 클러스터
이제 노드 목록을 조회해보자. 방금 전에 활성화시킨 매니저 노드 하나만 존재하는 단일 노드 클러스터가 구성된 것을 확인할 수 있다.
ubuntu@sjhong-node-01:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
9yubq203dgcl82o3n2bb2s31w * sjhong-node-01 Ready Active Leader 20.10.17
도커 데스크탑(Docker Desktop)에서도 위와 같은 방법으로 단일 노드 구성을 빠르게 진행할 수 있다. 단, 맥(Mac) 또는 윈도우(Windows)에서 도커 데스크탑(Docker Desktop)을 쓸 때엔 여러 개의 노드로 구성된 클러스터를 만들 수 없다는 점에 유의하자.
다중 노드 클러스터
도커 스웜(Docker Swarm)에서는 토큰(token)이 포함된 docker swarm join 명령을 이용하여 노드를 추가한다. 이때 삽입할 토큰 값은 추가할 노드의 종류에 따라 달라진다. 참고로 첫 번째로 init을 실행한 노드 외의 나머지 노드에서는 별도로 docker swarm init을 할 필요가 없다.
앞서 첫 번째로 docker swarm init을 실행 완료한 노드에 출력된 안내문의 일부를 다시 살펴보자.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-3h415tip2x8wh4xyv9g3uel3sp6ldrgsayusfvf4ebb8b36bvy-e0ghonmhzr286anttg7eybbd3 172.31.14.44:2377
안내문을 살펴보면 워커 노드 추가를 위한 명령어가 포함되어 있다. 워커 노드로 추가할 호스트에 접속해서 도커 엔진(Docker Engine) 설치와 필요 포트 개방을 마친 후, 위의 명령어를 실행시키면 This node joined a swarm as a worker.란 간결한 메시지와 함께 클러스터에 추가된다.
ubuntu@sjhong-node-02:~$ docker swarm join --token SWMTKN-1-3h415tip2x8wh4xyv9g3uel3sp6ldrgsayusfvf4ebb8b36bvy-e0ghonmhzr286anttg7eybbd3 172.31.14.44:2377
# 노드 추가가 완료되면 아래 메시지가 출력된다.
This node joined a swarm as a worker.
만약 매니저 노드를 추가하고 싶다면, 우선 매니저 노드로 돌아와 docker swarm join-token manager를 실행한다. 그러면 아래와 같이 별도의 토큰이 생성된다. 이것을 가지고 새 노드에서 docker swarm join 명령을 수행하면 된다.
# 매니저 노드 join용 토큰을 요청한다.
ubuntu@sjhong-node-01:~$ docker swarm join-token manager
To add a manager to this swarm, run the following command:
docker swarm join --token SWMTKN-1-3va9gxqumnvfax1tivnhheu785lypaepxw7mr3p9rsvifnogn1-0zsoazv4prylgfxqsbsbahi99 172.31.14.44:2377
# 매니저 노드로 추가할 호스트에 접속해서 위의 명령문을 실행한다.
ubuntu@sjhong-node-03:~$ docker swarm join --token SWMTKN-1-3va9gxqumnvfax1tivnhheu785lypaepxw7mr3p9rsvifnogn1-0zsoazv4prylgfxqsbsbahi99 172.31.14.44:2377
# 노드 추가가 완료되면 아래 메시지가 출력된다.
This node joined a swarm as a manager.
만약 워커 또는 매니저 노드 추가에 필요한 토큰값만 얻고 싶다면, docker swarm join-token 명령에 --quiet 플래그를 추가하면 된다.
ubuntu@sjhong-node-01:~$ docker swarm join-token --quiet worker
SWMTKN-1-3h415tip2x8wh4xyv9g3uel3sp6ldrgsayusfvf4ebb8b36gn1-e5pshwokqu9u1o05wzh3t3rde
노드 정보 조회하기
특정 노드의 상세 정보 출력
원하는 특정 노드에 대한 상세 정보를 확인하려면 docker node inspect <노드ID 또는 호스트네임> 명령을 사용한다. 다만 이렇게만 명령문을 실행할 경우 기나긴 JSON 포맷의 텍스트를 출력 결과로 받아보게 된다.
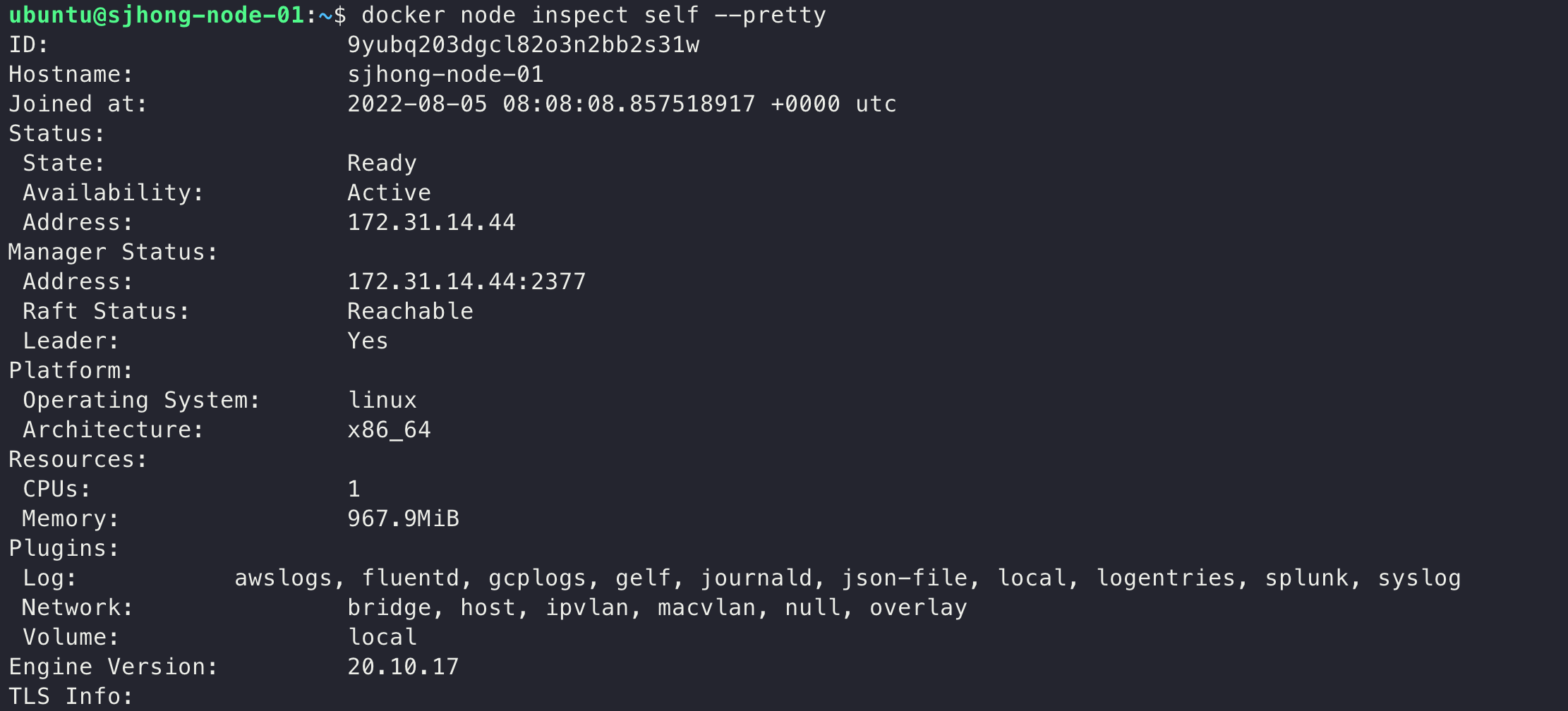
읽어보기 편한 포맷으로 가공된 출력물을 보고 싶다면 --pretty 플래그를 함께 붙여주자.
# 현재 접속한 노드 자기 자신의 정보를 출력할 때엔 노드ID 대신 'self'를 붙인다.
ubuntu@sjhong-node-01:~$ docker node inspect self --pretty
노드 목록 조회
다시 매니저 노드(sjhong-node-01)로 돌아와 클러스터 노드 목록을 조회해보자.
ubuntu@sjhong-node-01:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
9yubq203dgcl82o3n2bb2s31w * sjhong-node-01 Ready Active Leader 20.10.17
rf3q20h822xy879xj7sdzsqbl sjhong-node-02 Ready Active 20.10.17
ic3zkeh869dkenaww6iahztnk sjhong-node-03 Ready Active Reachable 20.10.17
docker node ls 명령어는 현재 클러스터에 구성된 노드들의 각 ID값과 HOSTNAME, STATUS, AVAILABILITY, 그리고 MANAGER STATUS를 보여준다. 노드 ID값 옆에 붙은 * 표시는 위의 조회 명령을 수행한 현재 노드를 의미한다.
ID는 클러스터 차원에서 각 노드에 부여된 고유의 값이다. HOSTNAME은 해당 노드가 가진 호스트네임(hostname)이다. 이 둘의 차이를 잘 구분해야 한다. 도커 스웜(Docker Swarm)의 클러스터에서 HOSTNAME은 중복이 가능하다. 같은 호스트네임을 가진 서로 다른 서버가 같은 클러스터에 속할 수 있는 것이다. 반대로 동일한 호스트가 클러스터를 떠났다가(leave) 다시 합류(join)한 경우에는 이전과 다른 새로운 ID값이 부여된다. 이처럼 클러스터에서 서로 다른 노드를 구분하는 가장 중요한 단서는 HOSTNAME이 아니라 ID값이라는 점에 유의하도록 한다.
다음으로는 AVAILABILITY와 MANAGER STATUS를 살펴보기로 하자. 먼저 AVAILABILITY 값을 보자. 이 값은 노드의 현재 상태를 나타낸다.
Active: 정상적으로 태스크(Task)를 할당받을 수 있는 상태를 의미한다.Pause: 이 상태의 노드에는 스케줄러(Scheduler)가 새로운 태스크(Task) 할당을 하지 않는다. 그러나 해당 노드에서 돌아가는 태스크(Task)는 구동 상태를 그대로 유지한다.Drain: 이 상태의 노드에는 스케줄러(Scheduler)가 새로운 태스크(Task) 할당을 하지 않는다. 해당 노드에서 돌아가던 태스크(Task)들은 모두 종료되며 가용 상태(Active)인 다른 노드로 다시 스케줄링 된다.
다음으로는 MANAGER STATUS에 주목하자. 이 상태값은 매니저 노드만이 가질 수 있다. 실제로 위의 예시를 보면 맨 처음 매니저 노드의 MANAGER STATUS 값이 Leader로 지정되어 있다. MANAGER STATUS에서 매니저 노드가 가질 수 있는 상태값은 다음과 같다.
Leader: 스웜 클러스터의 관리와 오케스트레이션을 관리하는 노드다.Reachable: 매니저 노드로서 다른 매니저 노드들과 정상적으로 통신 가능한 상태다. 만약Leader노드에 장애가 발생하면, 이 상태값을 가진 매니저 노드는 새로운Leader노드로 선출 가능한 후보군이 된다.Unavailable: 매니저 노드로서Leader를 포함한 다른 매니저 노드들과 통신이 불가능한 상태다. 이런 경우엔 노드를 다시 복구하거나, 다른 워커 노드를 매니저 노드로 변경하거나, 새 매니저 노드를 추가하는 작업이 필요하다.
도커 스웜(Docker Swarm)에서 클러스터는 1개 이상의 매니저 노드를 가질 수 있는데, 이 경우엔 리더(Leader)로 선별된 매니저 노드가 전체 클러스터를 실질적으로 관리하는 역할을 맡는다. 클러스터의 모든 변경 사항은 리더 노드를 통해 전파되며, 나머지 노드들은 리더 노드와 동기화 된 상태를 유지한다. 이는 뗏목 합의 알고리즘(Raft Consensus Algorithm)에 기초한 방법으로, 여러 개의 노드로 구성된 클러스터에서 일부 노드에 장애가 발생하더라도 나머지 노드들을 이용하여 서비스를 정상적으로 유지할 수 있는 고가용성(High Availability)을 위해 고안된 것이다.
노드 관리하기
노드 유형 변경
도커 스웜(Docker Swarm)의 노드 관리 명령어(docker node)에서는 promote나 demote처럼 특정 노드를 매니저 노드나 워커 노드로 바꿀 수 있는 간편한 명령어를 제공한다.
현재 시점에서는 sjhong-node-01과 sjhong-node-03이 매니저 노드로 지정되어 있다. 아직 워커 노드로 남아있는 sjhong-node-02 노드를 매니저 노드로 바꿔보자.
ubuntu@sjhong-node-01:~$ docker node promote sjhong-node-02
Node sjhong-node-02 promoted to a manager in the swarm.
ubuntu@sjhong-node-01:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
9yubq203dgcl82o3n2bb2s31w * sjhong-node-01 Ready Active Leader 20.10.17
rf3q20h822xy879xj7sdzsqbl sjhong-node-02 Ready Active Reachable 20.10.17
ic3zkeh869dkenaww6iahztnk sjhong-node-03 Ready Active Reachable 20.10.17
이로써 3개의 노드가 모두 매니저 노드로 바뀌었다. 이번에는 sjhong-node-01만 매니저 노드로 두고, 나머지 2개를 워커 노드로 동시에 바꿔보자. promote, demote 명령을 이용하면 여러 노드의 상태를 한 번에 변경할 수 있다.
ubuntu@sjhong-node-01:~$ docker node demote sjhong-node-02 sjhong-node-03
# 두 노드가 모두 워커 노드로 변경되었다.
Manager sjhong-node-02 demoted in the swarm.
Manager sjhong-node-03 demoted in the swarm.
promote, demote 명령은 아래와 같이 update --role 형태로 바꿔 쓸 수도 있다. 단, update --role 명령으로는 한 번에 하나의 노드만 바꿀 수 있다는 점에 주의하자.
# docker node promote sjhong-node-02
docker node update --role manager sjhong-node-02
# docker node demote sjhong-node-02
docker node update --role worker sjhong-node-02
또한 클러스터에 남은 마지막 매니저 모드는 demote 또는 제거가 불가능하다는 점에도 유의하자.
ubuntu@sjhong-node-01:~$ docker node demote sjhong-node-01
# FailedPrecondition 관련하여 에러 메시지가 출력된다.
Error response from daemon: rpc error: code = FailedPrecondition desc = attempting to demote the last manager of the swarm
demote 관련 에러 살펴보기
매우 드물게, 여러 노드를 한 번에 demote 하다 보면 다음과 같은 에러를 만나기도 한다.
ubuntu@sjhong-node-01:~$ docker node demote sjhong-node-02 sjhong-node-03
# 02번 노드는 정상적으로 워커 노드가 되었다.
Manager sjhong-node-02 demoted in the swarm.
# 그런데 03번 노드 처리 과정에서 아래와 같은 에러 메시지가 발생했다.
Error response from daemon: rpc error: code = FailedPrecondition desc = can't remove member from the raft: this would result in a loss of quorum
이 경우에는 침착하게 sjhong-node-03 노드를 워커 노드로 다시 변경해주자. 아까와는 달리 문제 없이 완료될 것이다.
# 다시 03번 노드를 워커 노드로 변경 처리한다.
ubuntu@sjhong-node-01:~$ docker node demote sjhong-node-03
# 이번에는 03번 노드도 정상적으로 워커 노드로 변경되었다.
Manager sjhong-node-03 demoted in the swarm.
노드 유형 변경과 관련된 SwarmKit의 코드를 살펴본 바로는, 위의 에러 응답은 복수의 매니저 노드를 운영하는 클러스터에서 고가용성(High Availability)을 위한 "정족수(raft quorum)"에 영향을 미치는 행위에 제동을 걸기 위한 것으로 추정된다. 개인적인 견해지만, demote 작업은 클러스터가 필요로 하는 정족수의 기준을 낮출 뿐이지 정족수 자체를 위협하는 작업이 아니므로 이런 오류 처리를 굳이 할 필요가 없다고 생각한다. 사실 이는 이미 2016년에 논의를 거쳐 수정사항이 반영된 이슈이기도 한데, 왜 아직 이런 현상이 간헐적으로 발생하는지는 불명확하다.

갑자기 새로운 용어가 나타나서 당황스럽겠지만, 일단 넘어가기로 하자. "정족수(raft quorum)"라는 용어는 앞으로도 노드를 관리하는 과정에서 종종 마주하게 될 것이다. 이 용어의 개념이 무엇인지는 다음 포스팅에서 좀 더 자세히 설명할 예정이다.
노드 상태 변경
때로는 노드에 태스크가 더 이상 할당되지 않도록 막거나, 돌아가고 있던 태스크들을 종료하고 다른 노드로 옮겨줘야 할 상황도 생긴다. 이를테면 호스트에 대한 정기적인 점검이나 업그레이드를 수행해야 하는 경우를 생각해 볼 수 있다. 이런 경우엔 docker node update 명령에 --availability 플래그를 더하여 원하는 노드의 상태를 변경한다.
docker node update --availability <상태> <노드>
--availability 플래그 뒤에는 원하는 <상태>와 대상이 될 <노드(노드ID 또는 호스트네임)>를 지정한다. <상태>에는 앞서 "노드 목록 조회" 파트에서 소개했던 active, pause 또는 drain 중 하나를 입력한다.
ubuntu@sjhong-node-01:~$ docker node update --availability drain sjhong-node-01
# 정상적으로 처리되었다면, 해당되는 노드의 호스트네임이 출력된다.
sjhong-node-01
# 이 시점에서 다시 노드 목록을 조회하면 01번 노드가 Drain 처리된 걸 확인할 수 있다.
ubuntu@sjhong-node-01:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
9yubq203dgcl82o3n2bb2s31w * sjhong-node-01 Ready Drain Leader 20.10.17
rf3q20h822xy879xj7sdzsqbl sjhong-node-02 Ready Active 20.10.17
ic3zkeh869dkenaww6iahztnk sjhong-node-03 Ready Active 20.10.17
도커 스웜(Docker Swarm)에서 매니저 노드는 기본적으로 워커 노드와 똑같이 태스크를 할당 받아 실행할 수 있다. 그러나 drain 상태의 매니저 노드는 새로운 태스크 할당을 받지 않고, 기존에 할당 받았던 태스크도 다른 노드로 옮긴다. 결국 해당 노드는 클러스터 관리 기능만을 수행하게 된다. 쿠버네티스에서 master:NoSchedule 테인트(Taint)가 설정된 마스터 노드와 동일한 상태가 되는 셈이다.
단, 서비스(Service)로 구성하지 않고 docker run 또는 docker compose up 명령으로 직접 구동시킨 컨테이너들은 Drain 상태에서도 종료되지 않고 그대로 남는다. 이들은 스웜 모드(Swarm Mode)에서 관리되지 않으며 해당 호스트에 개별적으로 남아있게 된다는 점에 유의하자.
노드 라벨링
각 노드에는 필요에 따라 라벨(Label)을 지정할 수 있다. 라벨은 키=값(key=value) 또는 키(key) 형태로 부여한다. 이후에 컨테이너 기반 애플리케이션 구동을 위해 서비스(Service)를 클러스터에 배포할 때, 노드에 부여된 라벨 정보를 이용하여 스케줄링 조건을 지정할 수 있다. 예를 들어 redis 서비스(Service)를 배포한다고 가정한다면, type=redis라는 라벨이 붙은 노드에만 해당 컨테이너가 돌아가도록 규칙을 만들 수 있을 것이다.
노드에 라벨을 추가할 때에는 docker node update 명령에 --label-add 플래그를 이용한다. 추가하려는 라벨 하나당 플래그를 하나씩 앞에 붙여줘야 정상적으로 실행된다.
# sjhong-node-03 노드에 'foo'라는 key와 `type=redis'라는 key=value를 라벨로 추가한다.
ubuntu@sjhong-node-01:~$ docker node update --label-add foo --label-add type=redis sjhong-node-03
# 노드 정보에서 추가된 라벨 내용을 확인한다.
ubuntu@sjhong-node-01:~$ docker node inspect sjhong-node-03 --pretty | grep -i labels: -A 2
# 입력된 라벨이 잘 추가된 것을 확인할 수 있다.
Labels:
- foo
- type=redis
불필요한 라벨은 --label-rm 플래그로 삭제한다.
# sjhong-node-03 노드에서 'foo'라는 라벨을 제거한다.
ubuntu@sjhong-node-01:~$ docker node update --label-rm foo sjhong-node-03
현재까지 확인한 바로는, 도커 스웜(Docker Swarm)에선 노드를 먼저 클러스터에 추가시킨 다음부터 라벨링 작업이 가능하다. docker swarm join 또는 init시점에서 바로 라벨링을 진행할 수는 없는 것으로 보인다. 아쉬운 부분이다.
클러스터에서 노드 제거
워커 노드 제거
매니저 노드가 현재 구동 중인 다른 노드를 클러스터에서 바로 제거할 수는 없다. 클러스터에서 노드를 제거하기 위한 일반적인 절차는 다음과 같다.
- 삭제할 노드를
drain시킨 뒤, 해당 노드에 있던 태스크들이 다른 노드로 잘 옮겨졌는지 확인한다. - 삭제할 노드에서
docker swarm leave명령을 실행하여 해당 노드와 클러스터의 연결을 끊는다. - 매니저 노드에서
docker swarm rm <삭제할노드>를 실행한다.
docker swarm leave 명령 자체가 drain 기능을 포함하고 있으므로 1번 절차는 선택사항에 가깝다. 그러나 가급적 먼저 해주는 걸 권장한다. 삭제될 노드 외엔 가용한 노드가 남아있지 않아서 기존에 돌아가던 태스크들이 PENDING 상태로 멈추게 될 가능성을 미리 체크하기 위해서다.
2번 절차가 끝난 후에도 클러스터 노드 목록에는 해당 노드가 여전히 남아있다는 점에 유의하자. 클러스터를 관리하는 매니저 노드 입장에선, 2번 절차까지 완료 된 노드도 '연결이 끊어져 Down 상태로 인식하게 된 노드'일 뿐이다. 클러스터에서의 노드 제거는 3번 절차까지 진행해주어야 완전히 마무리된다.
위의 절차를 차근차근 따라가보자. 여기서는 워커 노드인 sjhong-node-03 노드를 예제로 사용했다. 먼저 매니저 노드에 접속한 상태로 03 노드를 drain 상태로 바꿔준다.
ubuntu@sjhong-node-01:~$ docker node update --availability drain sjhong-node-03
다음으로는 03 노드에 할당되어 있던 태스크(Task)들이 다른 노드로 잘 옮겨졌는지 확인할 차례다. 도커 스웜(Docker Swarm)은 모든 애플리케이션이 서비스(Service) 단위로 배포되며, 서비스(Service)에 정의된 이미지 기반 컨테이너가 각 노드에 태스크로서 할당되어 돌아가는 체계를 갖추고 있다. 특정 서비스에 속하는 각각의 태스크가 어느 노드에 할당되어 있는지는 docker service ps 명령으로 확인할 수 있다.
# 여기서는 예시로 3개의 레플리카(replica)를 포함한 nginx 서비스를 배포한 상태로 가정한다.
# 03번 노드를 drain 처리 완료시킨 후,
# 현재 구동(running) 중인 nginx 서비스의 태스크들이 어느 노드에 있는지 확인한다.
# 아래와 같이 -f, --format을 조합하면 내게 필요한 정보만 골라서 출력시킬 수 있다.
ubuntu@sjhong-node-01:~$ docker service ps -f "desired-state=running" --format "{{.Name}}: {{.Node}}" nginx
# nginx 태스크들이 01, 02번 노드로 적절히 옮겨져 정상 구동 중인 것을 확인할 수 있다.
nginx.1: sjhong-node-01
nginx.2: sjhong-node-02
nginx.3: sjhong-node-01
이제 03 노드에 접속하여 docker swarm leave 명령을 실행한다. 그러면 해당 노드에선 스웜 모드(Swarm Mode)가 해제되며, 스케줄러는 해당 노드로 더 이상 태스크를 할당하지 않는다. 기존에 돌아가고 있던 태스크들이 있다면, 이들은 클러스터 안의 가용한 다른 노드들로 옮겨진다. 만약 가용한 노드가 없다면 이들은 어느 노드에도 할당되지 않은 채 PENDING 상태로 대기하게 된다.
ubuntu@sjhong-node-03:~$ docker swarm leave
# 해당 노드가 스웜(swarm)을 떠났다는 건조한 메시지가 출력된다.
Node left the swarm.
이 시점에서 매니저 노드로 돌아와 노드 목록을 조회하면 다음과 같이 나타난다.
ubuntu@sjhong-node-01:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
9yubq203dgcl82o3n2bb2s31w * sjhong-node-01 Ready Drain Leader 20.10.17
rf3q20h822xy879xj7sdzsqbl sjhong-node-02 Ready Active 20.10.17
ic3zkeh869dkenaww6iahztnk sjhong-node-03 Down Active 20.10.17
앞서 leave 처리한 sjhong-node-03이 여전히 목록에 남아있는 것을 볼 수 있다. 다만 STATUS가 Down으로 변경되었다. 즉, 해당 노드는 클러스터와의 연결이 끊어진 독자적인 도커 서버로 바뀌었기에 Down 상태로 표기되는 것이다.
이 상태에서 docker node rm <노드명>을 실행하면 최종적으로 노드 제거가 완료된다.
ubuntu@sjhong-node-01:~$ docker node rm sjhong-node-03
sjhong-node-03
ubuntu@sjhong-node-01:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
9yubq203dgcl82o3n2bb2s31w * sjhong-node-01 Ready Drain Leader 20.10.17
rf3q20h822xy879xj7sdzsqbl sjhong-node-02 Ready Active 20.10.17
만약 제거하려는 워커 노드에 접속이 불가능하거나 기타 이유로 강제 제거가 필요한 상황이라면, docker node rm 명령에 --force 플래그를 조합하여 바로 제거할 수 있다.
ubuntu@sjhong-node-01:~$ docker node rm --force sjhong-node-03
sjhong-node-03
매니저 노드 제거
매니저 노드를 제거할 때엔 demote 절차를 사전에 반드시 실행해 주어야 한다. 이후로는 워커 노드 제거 방법과 동일하다. 단, 제거 후에도 최소한 하나 이상의 매니저 노드가 클러스터에 존재해야 한다는 제약이 있다. 마지막 남은 매니저 노드는 demote 또는 제거가 불가능하다.
- 삭제할 노드를 워커 노드로
demote시킨다. - 삭제할 노드를
drain시킨 뒤, 해당 노드에 있던 태스크들이 다른 노드로 잘 옮겨졌는지 확인한다. - 삭제할 노드에서
docker swarm leave명령을 실행하여 해당 노드와 클러스터의 연결을 끊는다. - 매니저 노드에서
docker swarm rm <삭제할노드>를 실행한다.
만약 demote 작업 없이 바로 docker swarm leave 명령을 실행하면 아래와 같은 에러 메시지를 만나게 된다. 클러스터에 남은 매니저 노드의 수에 따라 메시지가 조금씩 바뀌지만, 내용은 대동소이하다. 어떤 경우에서든지 lost consensus, Raft quorum 등의 키워드를 에러 응답문에서 보게 될 것이다.
ubuntu@sjhong-node-03:~$ docker swarm leave
Error response from daemon: You are attempting to leave the swarm on a node that is participating as a manager. The only way to restore a swarm that has lost consensus is to reinitialize it with `--force-new-cluster`. Use `--force` to suppress this message.
물론 에러 메시지에 안내된 대로 docker swarm leave 명령에 --force 플래그를 붙이면 매니저 노드도 클러스터에서 바로 떼어 놓을 수 있다. 그러나 이것은 절대로 추천하지 않는 방법이다. 왜 그럴까? 한 번 실험해보자.
매니저 노드를 강제로 제거하면 벌어지는 일
먼저 3개의 노드가 모두 매니저 노드인 경우를 가정하자. 워커 노드 상태의 sjhong-node-03에서 docker swarm leave 명령 실행 결과는 바로 위에서 살펴보았으니, 이번엔 --force 플래그를 붙여 강제로 실행해보자.
ubuntu@sjhong-node-03:~$ docker swarm leave --force
Node left the swarm.
이 상태에서 다른 매니저 노드로 돌아와 전체 노드 목록을 조회하면 다음과 같이 나타난다.
ubuntu@sjhong-node-01:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
9yubq203dgcl82o3n2bb2s31w * sjhong-node-01 Ready Active Leader 20.10.17
kb57zh7jenb45p6pwgyg0roi1 sjhong-node-02 Ready Active Reachable 20.10.17
y8rcglngmyfsint6vljzrvj6h sjhong-node-03 Down Active Unreachable 20.10.17
3개의 매니저 노드 중 1개(sjhong-node-03)가 Down 되었다. 그러나 나머지 두 노드는 여전히 잘 동작한다. 클러스터 관리 기능도 정상적으로 돌아간다. 새 서비스를 클러스터에 배포하더라도 별다른 문제 없이 스케줄링되어 구동되는 것을 확인할 수 있다.

그렇다면 이번엔 3개의 노드 중 2개(01, 03)만 매니저 노드인 경우를 가정하자. 이 상태로 sjhong-node-03에서 docker swarm leave를 실행한 결과는 다음과 같다.
ubuntu@sjhong-node-03:~$ docker swarm leave
Error response from daemon: You are attempting to leave the swarm on a node that is participating as a manager. Removing this node leaves 1 managers out of 2. Without a Raft quorum your swarm will be inaccessible. The only way to restore a swarm that has lost consensus is to reinitialize it with `--force-new-cluster`. Use `--force` to suppress this message.
아까와는 달리 좀 더 무섭게 쓰인 경고문이 마음을 철렁이게 한다. 침착하게 읽어보면, 위의 "demote 관련 에러 살펴보기" 파트에서 잠시 소개했던 "뗏목 정족수(Raft quorum)"에 대한 경고임을 알 수 있다. 매니저 노드가 2개에서 1개로 줄어들면 이 정족수가 채워지지 않으면서 클러스터가 정상적으로 기능할 수 없으며, 이를 복구할 수 있는 유일한 방법은 클러스터 자체를 강제로 초기화하는 것뿐이라고 한다.
만약 이 상태에서 매니저 노드 제거를 강행하면 어떻게 될까? 03 노드에서 docker swarm leave --force를 실행하면 예와 마찬가지로 Node left the swarm.이라는 메시지가 출력된다. 잠시 시간을 보낸 후 01 노드로 자리를 옮겨 노드 목록을 조회해보자. 기대와는 다른 결과가 나타난다.
ubuntu@sjhong-node-01:~$ docker node ls
# 클러스터 관리 명령이 듣지 않는다. 정보 조회, 변경, 스케줄링 기능이 모두 멈춰버렸다.
Error response from daemon: rpc error: code = Unknown desc = The swarm does not have a leader. It's possible that too few managers are online. Make sure more than half of the managers are online.

3개 노드로 구성된 클러스터에서, 2개의 매니저 노드 중 하나만 없어진 상태인데 클러스터 관리 기능이 완전히 멈춰버렸다. 온전히 동작하는 매니저 노드가 아직 남아있는데도 말이다.
맺음말
이번 글에서는 도커 스웜(Docker Swarm)의 주요 용어를 소개하고, 클러스터를 구축한 뒤 노드를 관리하는 방법에 대해 간단히 알아보았다. 아울러 클러스터에서 매니저 노드를 강제로 제거했을 때 벌어지는 상황에 대해서도 실험을 통해 살펴보았다. 매니저 노드가 3개일 때엔 하나가 멈춰도 괜찮은 반면, 2개일 땐 하나만 멈춰도 클러스터 전체가 마비되는 현상은 입문자 입장에선 선뜻 이해하기 어려울 수 있다.
이 현상의 원인을 이해하려면, 결국 도커 스웜(Docker Swarm)의 클러스터 관리에 쓰이는 뗏목 합의 알고리즘(Raft Consensus Algorithm)의 역할과 정족수(Quorum)의 개념을 알아야 한다. 다음 글에서는 이 뗏목 합의 알고리즘(Raft Consensus Algorithm)에 대하여 알아보기로 하자.