분산 시스템의 내결함성을 높이는 뗏목 합의 알고리즘(Raft Consensus Algorithm)과 정족수(Quorum) 개념 알아보기
뗏목 합의 알고리즘(Raft Consensus Algorithm)은 다수 노드로 이루어진 분산 시스템에서 전체 노드의 최신화 및 동기화, 그리고 내결함성(False Tolerance)을 동시에 구현하기 위해 만들어진 합의 알고리즘의 일종이다. 이번 글에서는 이 알고리즘의 동작 원리와 정족수(Quorum) 개념을 간략히 살펴볼 것이다.

지난 글에서는 도커 스웜(Docker Swarm)의 다중 노드 클러스터에서 매니저 노드를 강제로 제거했을 때 벌어지는 일을 소개했었다. 매니저 노드가 3개일 때엔 하나가 멈춰도 괜찮았던 반면, 2개일 땐 하나만 멈춰도 클러스터의 관리 기능이 마비되었다. 얼핏 보면 당혹스러울 수 있지만, 뗏목 합의 알고리즘(Raft Consensus Algorithm)이 적용된 분산 시스템에서는 자연스러운 현상이다.
이번 글에서는 분산 시스템의 내결함성(Fault Tolerance)을 위해 고안된 뗏목 합의 알고리즘(Raft Consensus Algorithm)을 살펴본다. 또한 합의 알고리즘의 핵심 요소인 정족수(Quorum)의 개념을 파악하고, 이 정족수를 충족시키는 최적의 노드 수에 대해서도 함께 알아보기로 한다.
이 글은 클러스터 환경을 관리하는 엔지니어 또는 관련 직무를 지망하는 학습자의 눈높이에서 알고리즘의 동작 원리를 최대한 쉽게 풀어내는 데에 주안점을 두었다. 알고리즘의 기술적 구현법을 상세히 파악하고 싶은 분들을 위한 정보는 아래 맺음말에서 별도로 소개할 것이다.
뗏목 합의 알고리즘(Raft Consensus Algorithm)
뗏목 합의 알고리즘(Raft Consensus Algorithm)은 분산 시스템 환경에서 모든 노드가 동일한 상태를 유지하도록 하고, 일부 노드에 결함이 생기더라도 전체 시스템이 문제 없이 동작하도록 만들기 위해 고안된 합의 알고리즘(Consensus Algorithm)의 일종이다.
2014년에 Diego Ongaro와 John Ousterhout가 "In Search of an Understandable Consensus Algorithm"이라는 논문을 통해 최초로 발표했으며, 당시 Paxos 등의 같은 목적을 수행하는 다른 알고리즘보다 더 쉽게 이해할 수 있고 구현하기에도 용이한 구조를 목표하여 만들어졌다. 이후 현재는 쿠버네티스(Kubernetes)의 etcd 클러스터, MongoDB의 레플리카 셋(replica set) 등 다양한 영역에 접목되어 활용되고 있다.
왜 이름이 뗏목(Raft)인가?
위키피디아(Wikipedia)에서는 이 명칭이 "Reliable, Replicated, Redundant and Fault-Tolerant"에서 유래했다고 되어 있는데, 이는 실제 사연의 일부분에 불과하다.
흥미롭게도 이 알고리즘을 고안한 Diego Ongaro가 이름짓기의 과정을 고백(?)한 기록이 Google Groups에 남아있다. 여기에 언급된 주요 내용을 옮겨보면 다음과 같다.
- 딱히 줄임말을 염두에 둔 건 아니지만 'Reliable', 'Replicated', 'Redundant', 그리고 'Fault-Tolerant'와 같은 용어들을 떠올리던 중이었다.
- 로그들(logs)을 떠올리면서 이들로 무엇이 만들어질 수 있을지를 생각했다. (주: 로그(log)는 통나무를 일컫는 단어이기도 하다.)
- (기존에 널리 쓰여 왔던 합의 알고리즘인) Paxos 알고리즘이라는 하나의 '섬'으로부터 어떻게 '탈출'할지를 생각했다.

개인적으로는 위키피디아에 소개된 첫 번째 이야기보다는 두 번째, 그리고 세 번째 이야기가 조금 더 마음에 와닿았다. 작은 언어유희와 더불어 기존의 패러다임을 넘어서려는 패기가 엿보이는 사연이 아닐 수 없다. 이밖에도 재미있는 내용이 있으니 관심 있는 독자라면 위의 기록을 읽어보길 권한다. 이름짓기의 고통은 역시 만국 공통임을 확인할 수 있을 것이다.
동작 원리
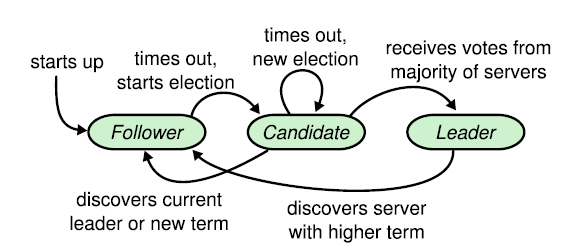
뗏목 합의 알고리즘(Raft Consensus Algorithm)이 적용된 분산 시스템에서 모든 노드는 아래의 세 가지 중 하나의 상태를 가진다. 일반적으로 하나의 리더와 나머지 팔로워들로 구성되며, 후보자는 오직 리더가 없거나 무응답 상태일 경우에만 일시적으로 존재한다.
- 리더(Leader) : 클러스터를 대표하는 하나의 노드다. 리더는 클라이언트가 클러스터로 보낸 모든 명령의 수신 및 전파, 그리고 응답을 전담한다. 또한 리더는 자신의 상태 메시지(heartbeat)를 주기적으로 모든 팔로워에게 전파한다.
- 팔로워(Follower) : 리더가 존재하는 한 나머지 노드는 이 상태를 유지한다. 리더로부터 전파된 명령을 처리하는 역할만 담당한다.
- 후보자(Candidate) : 리더가 없는 상황에서 새 리더를 정하기 위해 전환된 팔로워의 상태를 의미한다. 리더로부터 일정 시간 이상 상태 메시지(heartbeat)를 받지 못한 팔로워는 후보자로 전환된다.
뗏목 합의 알고리즘(Raft Consensus Algorithm)은 클러스터 전체에 대한 명령이 오직 리더로부터 팔로워에게 일방향으로 전파되도록 동작한다. 이 동작 원리의 짜임새를 간결하게 축약하면 다음과 같다.
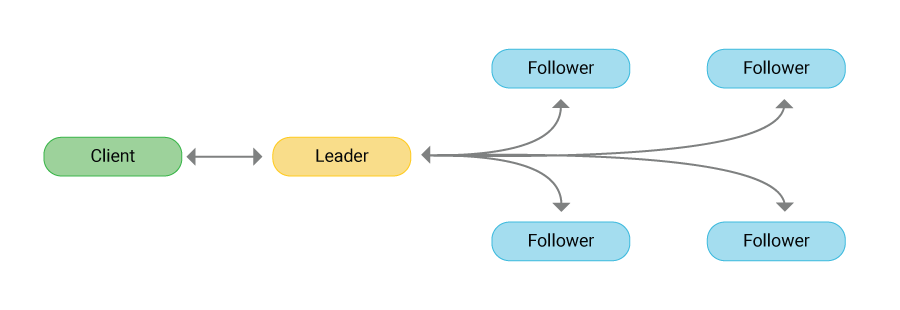
- 리더는 수신된 명령에 대한 로그(log)를 생성하여 로컬에 저장한 뒤 모든 팔로워에게 복제하여 전달한다. 각 팔로워는 전달받은 로그에 대한 응답을 다시 리더에게 보낸다.
- 리더가 수신한 정상 응답 수가 클러스터 전체 노드의 과반수에 이르면, 리더는 로그를 통해 전파된 명령을 클러스터의 모든 노드가 동일하게 수행하도록 한 뒤 클라이언트에게 명령 수행 결과를 리턴한다. 한편 리더는 해당 로그를 클러스터 전체 노드가 똑같이 보유할 때까지 로그 재전송을 주기적으로 반복한다.
- 시스템 문제나 네트워크 이슈로 제때 명령을 처리하지 못한 팔로워가 있더라도, 그 팔로워는 정상 상태로 복구된 뒤 클러스터와의 연결이 재개되면 리더로부터 그동안의 명령 처리 기록이 포함된 로그들을 다시 전달받아 순차적으로 수행한다. 클러스터 전체의 최신화 및 동기화는 이렇게 하여 유지된다.
리더 선출(Leader Election)
이처럼 뗏목 합의 알고리즘(Raft Consensus Algorithm)에서 리더의 역할은 절대적이다. 그렇다면 이 리더는 어떻게 정하는 것일까? 쉽게 말하자면, 과반수의 승인이 필요한 다수결의 원칙을 이용한다. 이것이 바로 리더 선출(Leader Election) 작업이다.
리더 선출(Leader Election)의 과정을 이해하려면 우선 아래 용어들을 알아야 한다.
- 임기(Term) : 정치 선거제에서의 "제1대", "제2대"와 같은 성격의 번호값이다. 이 번호값은 새로운 선거가 시작된 시점부터 그 선거로 선출된 리더가 리더로서 기능하는 동안까지의 시간을 대표한다.
- 선거 타임아웃(Election Timeout) : 팔로워 상태의 노드가 후보자로 변환되기까지 대기하는 시간으로, 일종의 타이머와 같이 기능한다. 이 타임아웃은 모든 팔로워 및 후보자 노드에게 150~300ms 사이의 각기 다른 임의의 값으로 주어진다.
- 하트비트(Heartbeat) : 리더가 다른 모든 팔로워에게 일정 시간 간격으로 반복 전달하는 메시지다. 이 메시지에는 클라이언트의 명령 전파를 위한 로그(log)가 포함되지 않으며, 오직 리더가 자신의 상태를 유지하는 수단으로만 기능한다.
이제 리더 선출(Leader Election)의 과정을 살펴보자.
- 클러스터에 리더가 없는 상태에선 모든 노드가 팔로워 상태를 유지하며 각자에게 주어진 선거 타임아웃(Election Timeout)이 될 때까지 대기한다.
- 선거 타임아웃(Election Timeout)이 가장 먼저 끝난 노드가 후보자로 전환되고, 새로운 선거 임기(Term)가 시작된다. 후보자 노드는 즉시 자신에게 한 표를 준 뒤 다른 노드들에게 투표 요청 메시지를 전송한다.
- 만약 이 요청 메시지를 수신한 노드가 해당 임기 중에 아직 투표한 적이 없다면, 그 메시지의 발신처인 후보자에게 투표 메시지를 보낸 후 자신의 선거 타임아웃(Election Timeout)을 초기화한다. 이는 현재 투표 과정에 있는 후보자 노드(들) 외에 또다른 후보자가 출현하지 않도록 하는 장치다.
- 전체 노드 수의 과반에 해당하는 응답을 얻은 노드는 해당 임기(Term)에 대한 새로운 리더로 선정된다.
이렇게 새로 선출된 리더는 나머지 노드들에게 하트비트(Heartbeat)를 주기적으로 전송한다. 팔로워는 리더로부터 하트비트(Heartbeat)를 수신할 때마다 자신의 선거 타임아웃(Election Timeout)을 다시 초기화하며 팔로워 상태를 유지한다. 리더가 정상적으로 동작하는 한, 하나의 리더와 나머지의 팔로워로 이루어진 클러스터 구성은 계속 유지된다.
만약 리더 노드에 문제가 생긴다면?
자신에게 주어진 선거 타임아웃(Election Timeout) 이내에 리더로부터 어떠한 메시지도 받지 못한 팔로워 노드는 즉시 후보자로 전환된다. 이때 클러스터의 임기(Term) 번호가 1 증가하게 되며, 곧바로 새로운 리더 선출이 시작된다. 이후에 진행되는 과정은 위의 2~5번과 동일하다.
클러스터의 각 노드는 현재의 임기(Term) 번호를 저장해두고, 서로 메시지를 주고 받을 때마다 이 번호를 함께 포함시킨다. 문제가 생겼던 이전의 리더 노드가 복구되어 클러스터와 다시 연결되면, 이 노드는 클러스터가 공유하는 임기(Term) 번호를 자신의 번호와 비교하게 된다. 현재 클러스터의 임기(Term) 번호보다 자신의 번호가 낮은 것을 확인한 이전의 리더 노드는 팔로워로 전환된다.
만약 누구도 과반을 얻지 못했다면?
자주 있는 일은 아니지만, 경우에 따라 재선거를 치러야 할 때도 있다. 예를 들어 4개 노드의 클러스터에서 우연히 2개의 후보자가 동시에 나타나서 각 2표씩 얻은 경우를 상상해 볼 수 있다.
이러한 분할 투표(split votes) 현상으로 인해 누구도 과반을 얻지 못한 경우에는 그대로 해당 임기를 종료하고 새 임기와 함께 재선거를 시작한다. 이때 이전 선거처럼 동점자가 다시 나타나지 않도록, 뗏목 합의 알고리즘(Raft Consensus Algorithm)은 매 선거가 시작될 때마다 후보자 노드들의 선거 타임아웃(Election Timeout) 값을 랜덤하게 재조정한다. 이후의 진행 과정은 위의 2~5번과 동일하다.
그러나 만약 클러스터 안에 죽은 노드가 너무 많아서 어떤 노드도 과반의 득표를 얻을 수 없는 상황이라면 리더 선출이 불가능해진다. 클러스터로 들어오는 명령이 오직 리더로부터 팔로워에게 일방향으로 전파되는 알고리즘의 특성상, 리더의 부재는 클러스터 관리 기능 전체를 멈추게 만든다.
정족수(Quorum)
이제 지난 글에서 머리를 아프게 했던 정족수(Quorum)에 대한 궁금증을 해소해보자. 이 용어는 뗏목 합의 알고리즘(Raft Consensus Algorithm)을 비롯하여 다양한 종류의 합의 알고리즘에서 공통적으로 쓰이는 용어다.

앞서 클러스터 전체의 최신화 및 동기화, 그리고 리더 선출 과정에서 전제한 원칙이 있다. 과반수의 승인이 필요한 다수결의 원칙이다. 합의 알고리즘이 적용된 분산 시스템에서 어떤 변화를 적용하고자 할 때에는 클러스터의 전체 노드 수(N) 가운데 자기 자신을 포함하여 최소 과반의, 즉 (N+1)/2 이상의 응답을 얻어야 한다. 이때 요구되는 최소한의 노드 수, 즉 (N+1)/2와 같거나 큰 자연수에 해당하는 수가 바로 정족수(Quorum)다. 뗏목 합의 알고리즘(Raft Consensus Algorithm)에서 쓰이는 정족수는 "뗏목 정족수(Raft quorum)"라고 칭하기도 한다.
정족수(Quorum)는 클러스터의 관리 기능은 물론 내결함성(Fault Tolerance)을 유지하는 데에도 필요하다. 과반수의 노드가 응답 가능한 정상 상태를 유지한다면 클러스터의 기능도 계속 유지되므로, 나머지 일부 노드에 문제가 생기더라도 그 숫자가 최대 (N-1)/2개 이하라면 클러스터 전체가 다운될 위험은 없어진다. 예를 들어 전체 노드가 3개라면, 그 중 하나가 잘못되더라도 나머지 2개가 클러스터의 온전한 동작을 보장할 수 있으므로 잘못된 노드의 복구 시간을 다운타임(downtime) 없이 벌 수 있는 것이다.
이 정족수가 충족되지 않는다면 클러스터가 제대로 기능할 수 없게 된다. 지난 글의 마지막 파트에서 가정했던, 매니저 노드가 2개로 구성된 도커 스웜(Docker Swarm) 클러스터의 경우를 다시 살펴보자. 여기서 클러스터 기능 유지를 위해 필요한 정족수는 (2+1)/2와 같거나 큰 자연수, 즉 2가 된다. 따라서 둘 중 하나만 정지되더라도 문제가 발생한다. 리더 노드의 선출이 불가능해지고, 클러스터의 최신화 및 동기화도 불가능해지므로, 결국 클러스터 전체의 관리 기능이 무너진다.
내결함성을 위한 최적의 노드 수
합의 알고리즘(Consensus Algorithm)을 채택한 분산 시스템에서는 전체 노드 수를 가급적 3개 이상의 홀수로 유지하는 것이 권장된다. 이유는 아래와 같다.
- 최소 3개의 노드가 있어야 클러스터가 내결함성(Fault Tolerance)을 갖출 수 있다.
- 전체 노드 수가 홀수일 때 허용 가능한 장애 노드 수의 비율이 좀 더 높다.
N개의 노드로 구성된 클러스터를 가정해보자. 최소 과반수가 정상 동작해야 한다는 알고리즘의 조건을 고려할 때, 허용 가능한 장애 발생 노드 수를 계산하면 다음과 같다.
N이 홀수(2k+1)일 때 :k개 노드의 장애까지 허용 가능N이 짝수(2k)일 때 :k-1개 노드의 장애까지 허용 가능
| 전체 노드 수 | 필요 정족수 | 허용 가능 장애 노드 수 |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
| 7 | 4 | 3 |
| 8 | 5 | 3 |
| ... | ... | ... |
2k (짝수)
|
k+1
|
k-1
|
2k+1 (홀수)
|
k+1
|
k
|
위의 표에서 나타나듯, 전체 노드 수가 3개 이상이어야 허용 가능한 장애 노드가 생긴다. 그 미만으로는 내결함성을 갖출 수 없다. 2개의 노드로 클러스터를 구성하는 것은 자원 관리의 측면에서나 내결함성의 측면에서나 모두 비효율적인 방식임을 알 수 있다.
3 이상의 짝수 개로 노드를 구성하는 것도 얼마든지 가능하다. 그러나 클러스터가 정상적으로 기능하기 위해 요구되는 정족수의 비율이 홀수인 경우에 비해 높다는 단점을 감수해야 한다. 가능하다면 더 적은 수의 노드로 동등한 수준의 내결함성을 가질 수 있는 홀수 개의 노드로 클러스터를 구성하는 것이 더 효율적이다.
아울러 뗏목 합의 알고리즘(Raft Consensus Algorithm)의 경우에는 분할 투표(split votes)로 인한 리더 선출(Leader Election)의 불필요한 반복과 명령 처리 지연 가능성을 줄이기 위해서라도 홀수 개의 노드 운영이 더욱 권장된다.
맺음말
이번 글에서는 뗏목 합의 알고리즘(Raft Consensus Algorithm)과 정족수(Quorum), 그리고 이에 기반하여 내결함성을 갖추기 위한 최적의 노드 수에 대해 간략히 살펴보았다.
앞서 언급했듯이, 이 글은 상세한 기술적 사항보다는 개념적 원리를 중심으로 쉽게 풀어 정리하는 데에 목적을 두었다. 이 과정에서 많은 내용이 축약되거나 제외되었음을 밝힌다. 이 알고리즘에 대해 보다 자세한 정보를 원하시는 분들을 위한 링크를 아래와 같이 첨부한다.
- The Raft Consensus Algorithm : 알고리즘에 대한 소개 자료와 함께, 이 알고리즘의 동작 메커니즘을 직접 확인해 볼 수 있는 곳이다. 최초 원저자의 논문도 다운로드 가능하다.
- Paxos보다 쉬운 Raft Consensus : 원저자의 논문 내용을 명료하게 정리해 주신 이도현님의 글이다.
- Raft : Understandable Distributed Consensus : 알고리즘의 기본 개념, 그리고 핵심 기능인 리더 선출(Leader Election)과 로그 복제(Log Replication) 과정을 알기 쉽게 시각화하여 보여준다. 이 글에서 설명한 내용이 잘 이해되지 않는다면 이곳을 살펴보길 권한다.
- Raft Algorithm, Explained (Part 1, Part 2) : 알고리즘의 핵심 기능인 리더 선출(Leader Election)과 로그 복제(Log Replication)가 상세히 설명된 글이다. 위에서 설명한 동작 원리가 구체적으로 어떻게 구현되는지 확인하고 싶다면 참고하자.