ChatGPT에서 채팅 만으로 웹 애플리케이션을 만드는 프롬프트 활용 사례와 시사점
ChatGPT로 앱을 만든다? 가능한 일일까? 그래서 실험해 보았다. 오직 프롬프트 입력 만으로 ChatGPT에서 웹 애플리케이션 구현에 필요한 모든 코드를 생성하고 이를 실제로 동작시켜 보았다. 그 실험의 과정과 결과, 그리고 이를 통해 얻게 된 시사점을 자세히 소개한다.

한때 사업 기획 담당자로서 신사업용 프로덕트들의 개발 과정을 리드한 적이 있었다. 그 시절 나의 주요 공상 소재 중 하나가 대화형 프로토타이핑 도구였다. 스케치 수준의 아이디어와 컨셉, 최소한의 정책, 사용할 기술 스택을 입력하면 대략의 와이어프레임과 코드 생성을 거쳐 PoC(Proof of Concept) 수준의 결과물이 배출되는 시스템을 상상했다. 높은 품질을 기대하긴 어렵겠지만, 날것의 아이디어를 빠르게 시험하기에 충분한 수준으로만 나와 준다면 전체 개발 과정의 효율이 비약적으로 향상되리라 생각했다. 꿈 같은 공상이었다. 당시에는.
이젠 상황이 달라졌다. 허황된 공상으로 여겨졌던 일들이 생성 인공지능(Generative AI)의 시대를 만나 조금씩 현실의 영역으로 들어오고 있다. 이미 미드저니(Midjourney)가 생성한 그림이 미국 콜로라도 주립 박람회 미술대회에서 우승한 바 있었고, 얼마 전에는 게임 속 NPC 캐릭터들과 직접 대사를 주고 받을 수 있도록 ChatGPT가 결합된 게임 모드가 공개되기도 했다. 대화형 프로토타이핑 도구의 출현은 아직 요원해 보이지만, 최근의 AI 기술 발전 속도는 그 출현 시기가 예상보다 앞당겨질 수 있겠다는 기대를 품게 만든다.
이쯤에서 궁금한 게 생겼다. 과연 AI 챗봇과의 대화 만으로 간단한 웹 애플리케이션을 만들어낼 수 있을까? 알고리즘 문제나 코딩 과제를 대신 풀어주는 수준을 넘어, 실제로 동작 가능한 애플리케이션의 핵심 코드들을 프롬프트로 모두 생성하는 일이 가능할까?
그래서 실험해 보았다. 오직 프롬프트 입력 만으로 ChatGPT에서 웹 애플리케이션 구현에 필요한 모든 코드를 생성하고 이를 실제로 동작시켜 보았다. 이번 글에서는 그 실험의 과정과 결과, 그리고 이를 통해 얻게 된 시사점을 소개할 것이다.
https://github.com/seongjinme/Nemo-Coded-by-ChatGPT
ChatGPT가 가진 특징과 제약사항
본론에 앞서 ChatGPT가 그동안 존재해 왔던 언어 모델 기반 서비스와 다른 부분들을 먼저 짚고 넘어가겠다. 이번 실험의 과정을 이해하는 데에 꼭 필요한 내용이다.
ChatGPT의 특징 : 맥락(Context)의 유지
ChatGPT는 같은 세션 안에서 이루어진 일정 분량의 대화 내용을 기억한다. 실제로 하나의 질문을 던진 뒤 더 자세히 설명해줘 또는 Tell me more와 같은 프롬프트를 입력해보면, 이전의 응답 내용을 기억하여 더 상세한 답안을 생성해주는 동작을 확인할 수 있다. 간단한 문답을 주고 받을 때라면 매번 같은 내용 입력을 반복하지 않아도 사람과 대화하듯 문답이 자연스럽게 이어진다. 이러한 맥락 유지는 ChatGPT의 기반이 된 GPT-3.5 모델이 주고 받은 대화 전체를 프롬프트로 매번 입력받도록 하여 이루어지는 것으로 알려져 있다.
이처럼 대화의 맥락(Context)이 보존되는 환경에서는 일회성 입출력만 가능한 기존 챗봇에 비해 훨씬 다채로운 방식으로 작업을 이어갈 수 있다. 하나의 문제를 해결하는 과정에서 대화를 여러 차례 주고 받으면서 결과물을 개선하거나 확장하는 일이 가능해진 것이다.

ChatGPT의 제약사항 : 기억 및 응답 분량의 제한
사람과 얘기할 때도 말이 길어지다 보면 처음의 화제가 잊혀지고 대화가 산으로 가는 상황이 벌어지곤 한다. AI라서 완벽할 것 같은 ChatGPT와의 대화에서도 이런 상황이 종종 생긴다. 이는 기반 언어 모델과 서비스 자체가 가진 스펙상 한계 때문이다.
공식 문서에 따르면, ChatGPT는 하나의 세션에서 영어 기준으로 약 3,000 단어 (4,000 토큰) 까지의 대화 내용을 기억할 수 있다고 한다. 전체 대화 내용이 이 분량을 넘어서면, ChatGPT는 그동안 기억해 왔던 맥락의 내용을 잃어버리기 시작한다. 한 번에 3,000단어가 넘어가는 긴 분량의 프롬프트가 입력된 경우에도 지시 내용을 제대로 인식하지 못하게 된다. 그 결과로, 우리는 한동안 영특하게 답해왔던 ChatGPT가 어느 순간 슬금슬금 동문서답을 시작하는 상황을 보게 된다.
개별 응답의 길이 또한 제한된다. 정확한 수치는 공개되지 않았으나, 여러 사용자들의 실험 결과에 따르면 대체로 500 단어 전후로 추정된다. 그 분량을 넘길 경우 ChatGPT의 응답이 갑자기 끊기게 된다. 경우에 따라서는 브라우저에 네트워크 오류 등의 문제가 기록되기도 한다. 일반적인 작문 작업에서는 continue 또는 go on 등의 프롬프트로 해결되기도 하지만, 맥락이 유실된 상태에서 응답량 제한의 문제까지 겹친다면 곤란한 상황이 벌어질 수 있다.
제작할 웹 애플리케이션 소개
복잡한 맥락을 주입시키며 응답 내용을 코드로 받아내야 하는 이번 실험의 관건은 위와 같은 제약 사항들을 최대한 회피하는 것이었다. 그래서 다음과 같은 전제 조건을 정했다.
- (학습 데이터가 충분한) 널리 알려진 언어와 프레임워크를 사용한다.
- 애플리케이션 구조의 복잡도를 최대한 낮춘다.
- 프롬프트 입력 횟수를 최소화한다.
- 코드의 양을 최소화한다.
위의 4가지 조건을 고려하여, 이제부터 "Nemo"라는 이름의 미니 소셜 애플리케이션을 ChatGPT와 함께 만들어 볼 것이다. "Nemo"의 주요 기능은 다음과 같다.
- Django 프레임워크와 Bootstrap을 사용한다.
- 사용자명(
username)과 비밀번호(password)로 등록하고 로그인할 수 있다. - 인덱스(
index) 페이지에는 모든 사용자의 포스트들이 노출된다. - 로그인한 사용자는 1,000자 이내의 포스트를 올릴 수 있다.
- 로그인한 사용자는 자신이 올린 포스트를 삭제할 수 있다.
- 로그인한 사용자는 다른 사용자의 포스트에 '좋아요'를 추가하거나 취소할 수 있다.
이 실험의 목표는 스케치 수준의 아이디어 만으로 프롬프트를 구성하여 PoC 수준의 구동 가능한 결과물을 만드는 것이다. 따라서 코드 생성 이외의 다른 과정들(상위기획 및 상세 기획안 개발, 와이어프레임, 프로토타이핑, 디자인 등)은 과감히 생략했다. 이제 실제 프롬프트 입력 단계로 넘어가보자.
프롬프트 입력 및 코드 생성
Django 애플리케이션의 핵심 구성 요소는 모델(Model), 템플릿(Template), 뷰(View), 그리고 URL 패턴이다. 각 요소마다 필요한 코드들을 ChatGPT로 생성할 것이다. 작업 순서는 여러 차례의 실험 가운데 가장 짧고 간결했던 성공 사례의 과정을 따랐다. 프로젝트 및 앱 생성 과정은 생략했다.
모델(Model) 만들기
먼저 "Nemo" 앱에 필요한 모델을 생성한다. 내가 입력한 프롬프트는 다음과 같다.
I need to create a Twitter-like Django app called "Nemo".
Here are the basic features of this app.
- All visitors can view all posts of registered users in the index page.
- A single post contains 1 to 1000 characters.
- Any visitor can register and login to the app using username and password.
- Logged-in users can create their posts.
- Logged-in users can delete their own posts.
- Logged-in users can give or revoke a 'Like' on the other user's post.
Considering the features above, create models.
Use only one model. Give me just codes, not with descriptions.
최대한 간소화된 모델 구성을 위해 프롬프트 안에 제약 조건을 걸어두었다. 내용은 이렇다.
- 오직 하나의 모델(포스트)만 정의하도록 유도했다. 사용자 모델(
User)은 Django에 기본으로 포함된 모델을 쓰면 되고, '좋아요'에 대한 정보는 Django가 지원하는ManyToManyField를 통해 사용자-포스트 모델 간N:N관계를 만들면 해결되기 때문이다. - 부연설명 없이 코드만 출력하도록 했다. 오가는 단어(토큰)의 수를 줄여서 작업 맥락(Context)을 최대한 오래 유지하고자 했다.
생성 결과는 다음과 같았다. 원했던 모델 코드를 한 번에 바로 얻어냈다.
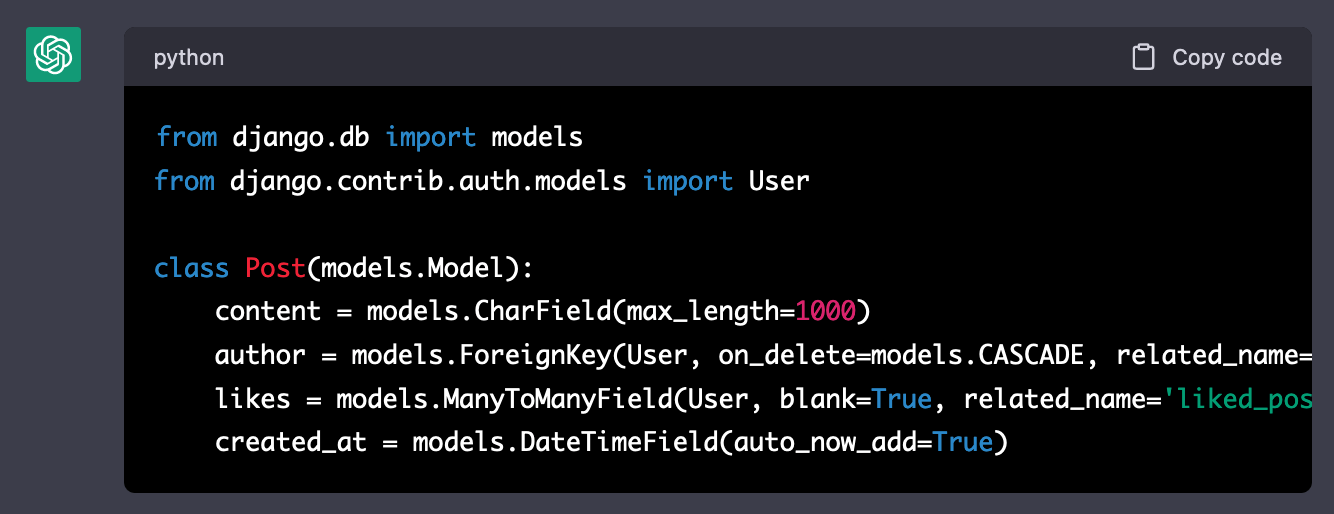
뷰(View) 만들기
Next, create views according to features and models above.
Use Django's default generic views and auth views
to keep the codes as simple as possible.
All templates will be placed under `nemo/` in the project's templates directory.
Here are views I need:
- Index
- Register
- Login
- Logout
- Create a post
- Delete a post
- Like/Unlike a post
위 프롬프트에서 내가 의도한 것은 다음과 같다.
- 맨 처음의
Next,는 이전 작업이 잘 완료되었다는 신호로서 삽입했다. - 앞서 주고 받은 내용의 맥락(
features,models)을 언급하여 작업의 연속성을 지키도록 유도했다. - Django가 빌트인(Built-in)으로 지원하는 뷰 클래스들을 사용하여 코드를 최대한 간결하게 만들도록 했다.
- "Nemo" 앱에 해당하는 올바른 템플릿 경로(
nemo/)를 사용하도록 지시했다. - 실제로 생성해야 할 뷰의 목록을 나열하여 제공했다.
결과는 다음과 같다. 대강 보기에도 제법 깔끔한 결과물이 출력되었다. 아래 이미지에는 일부 코드만 포함되어 있으며, 전체 코드는 여기서 확인할 수 있다.
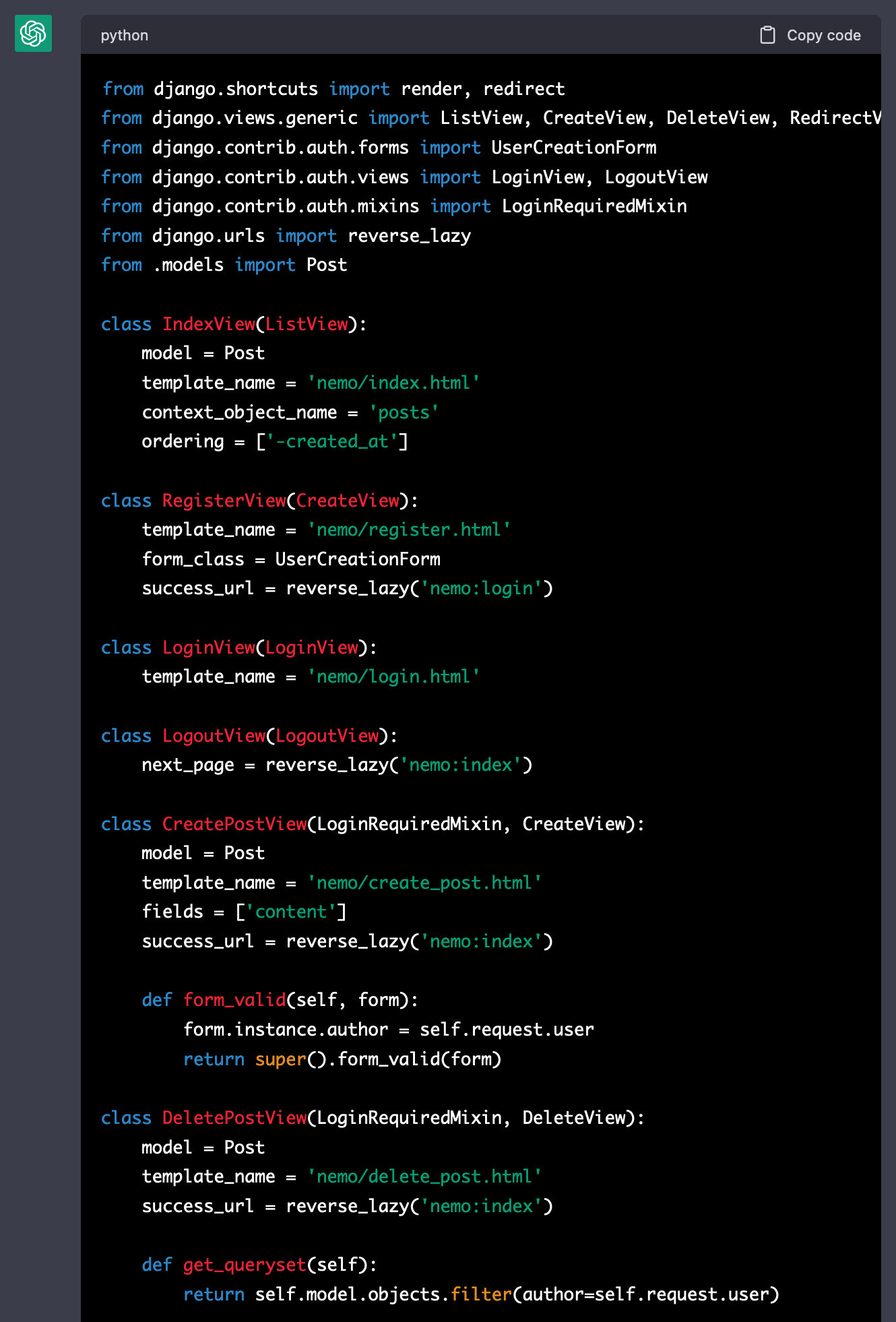
URL 패턴 만들기
Next, create URLs based on the views you created above.
각각의 URL에 연결할 뷰(View)가 이미 생성되어 있으므로, 이 맥락만 상기시킨다면 URL 패턴 생성도 손쉽게 진행된다. 결과는 다음과 같다.
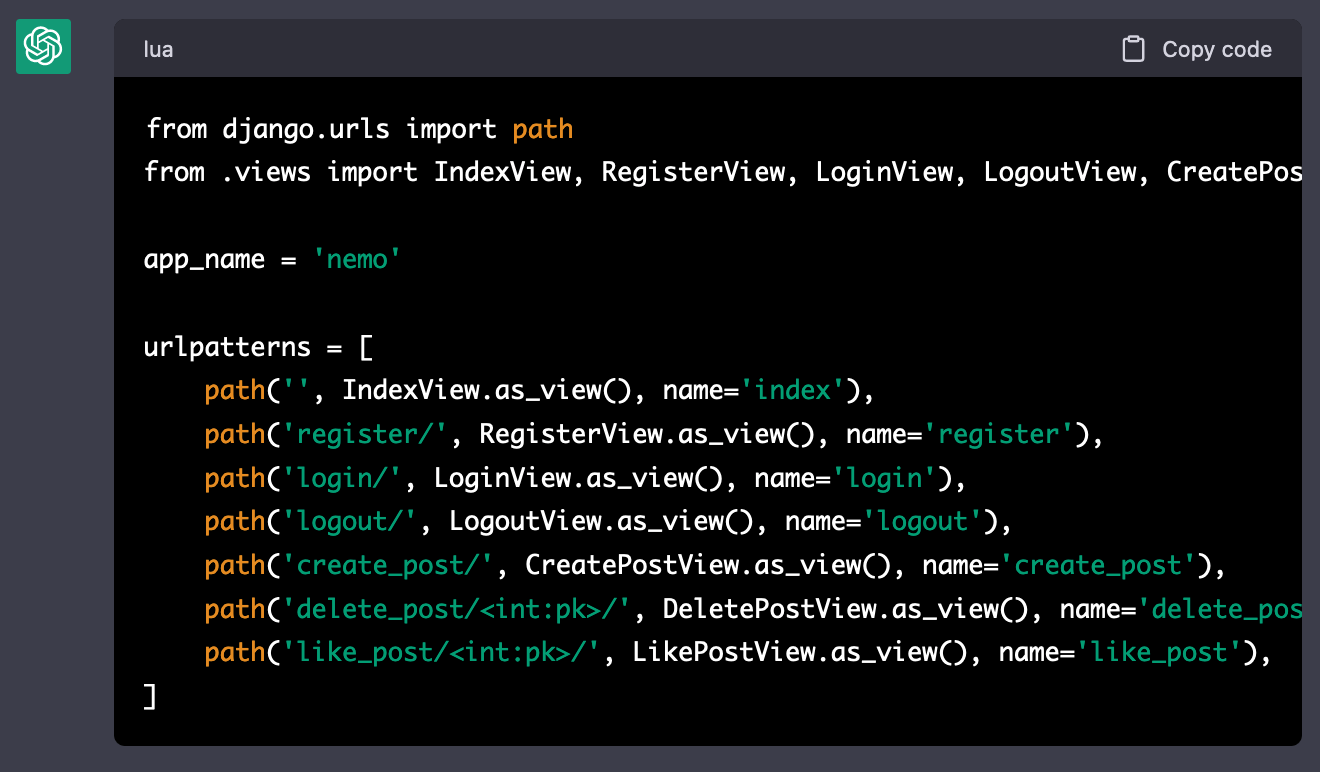
템플릿(Template) 만들기
베이스 템플릿 만들기
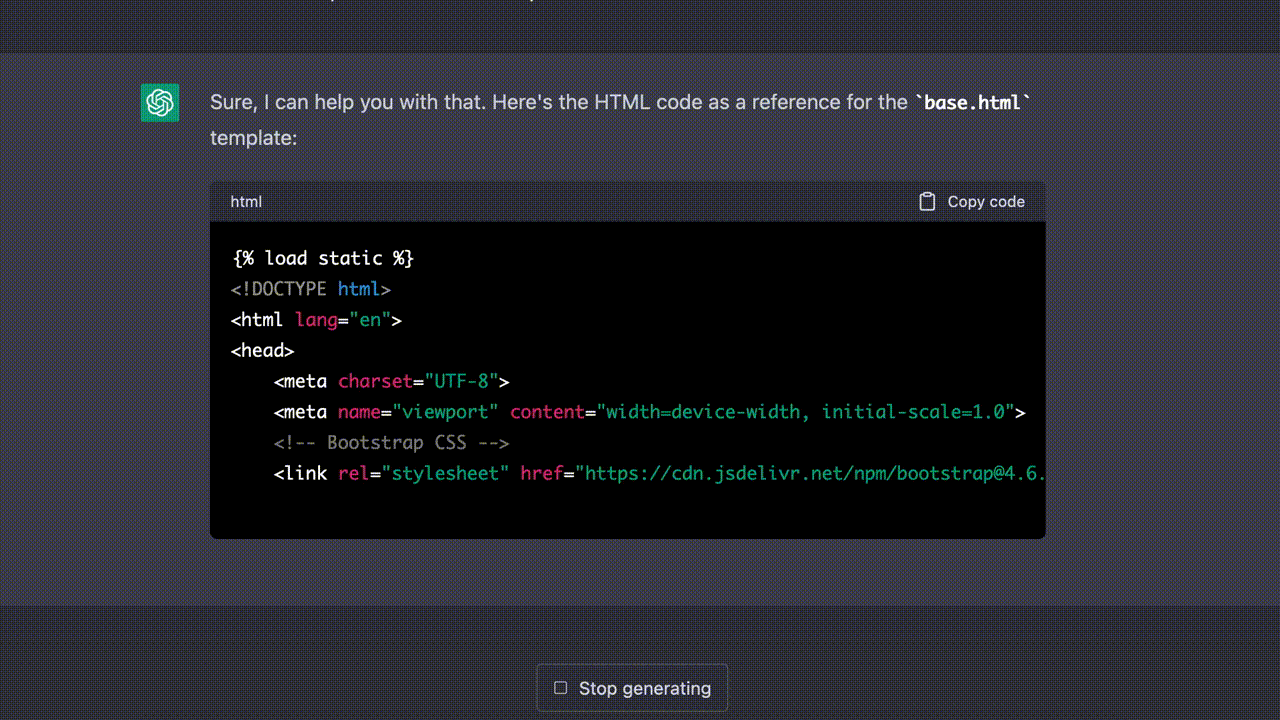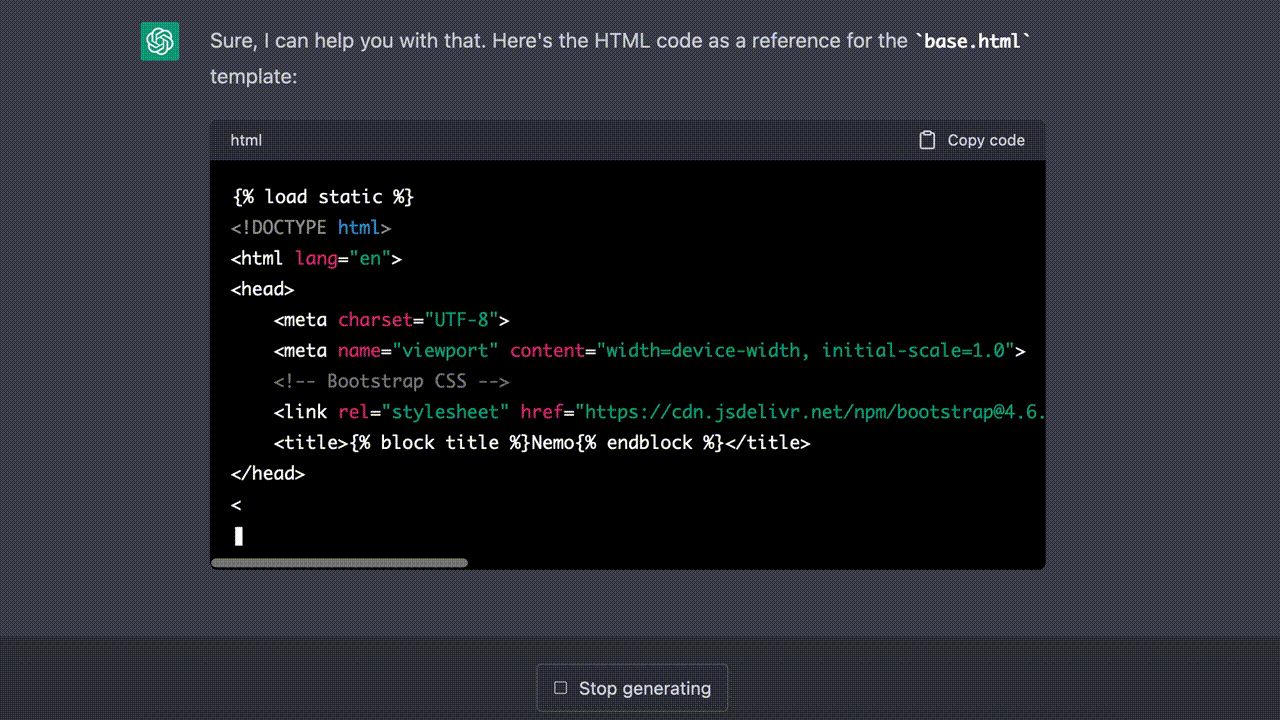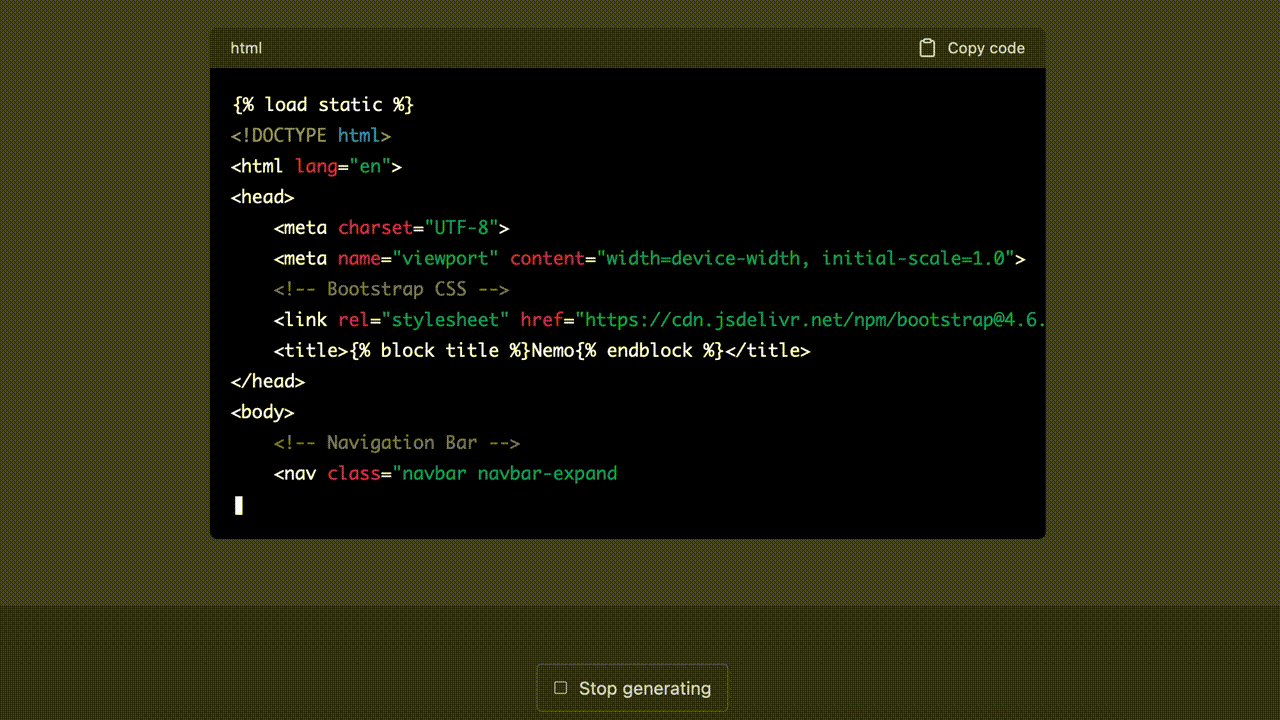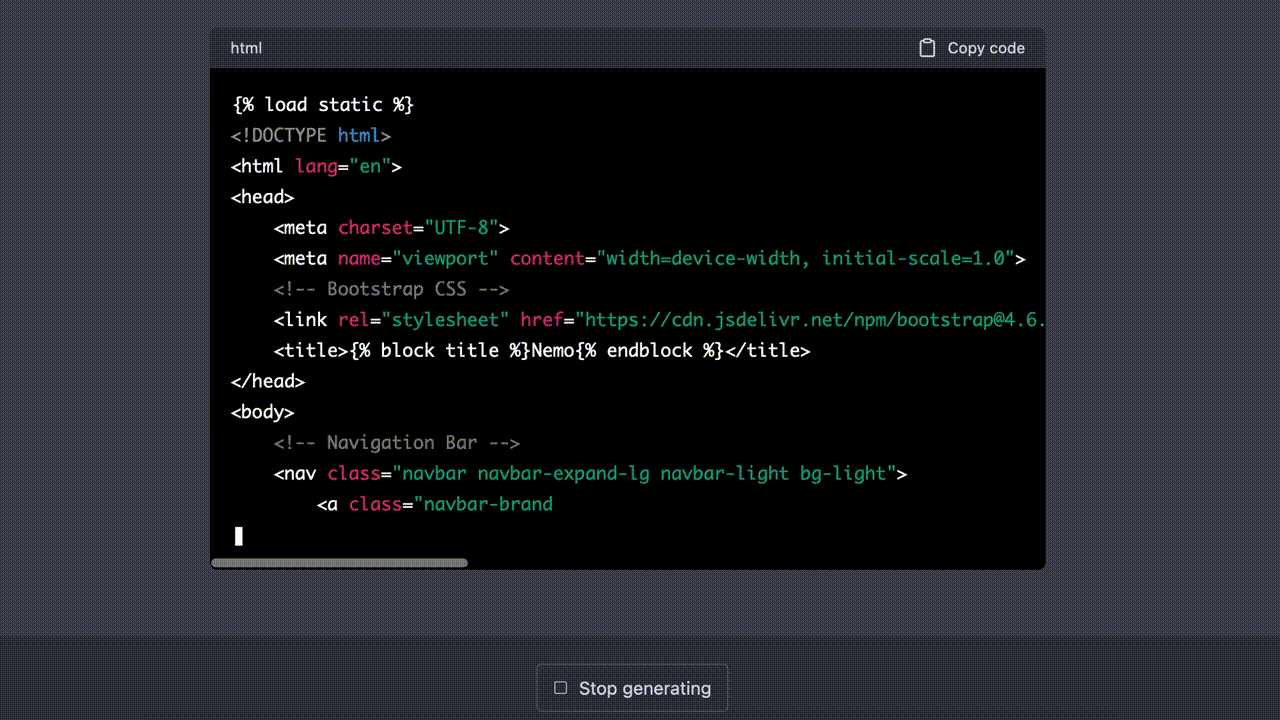
이제 각각의 뷰(View)와 URL 경로에 대응할 템플릿을 만들 차례다. 가장 먼저 필요한 것은 다른 상세 페이지들마다 공통으로 포함되어야 할 구성요소들이 담긴 베이스 템플릿(base.html)이다. 내가 사용한 프롬프트는 다음과 같다.
Next, create the base template according to features, models, views and URLs above.
Use Bootstrap from jsDelivr.base template라는 단서를 준 뒤, 지금까지 프롬프트로 입력되어 왔던 앱의 주요 기능(features), 모델(models), 뷰(views) 그리고 URL 패턴(URLs)을 모두 반영하도록 했다.- Bootstrap은 jsDelivr CDN에서 받아 사용하도록 했다. 이렇게 경로를 특별히 지정하지 않을 경우 ChatGPT는 프로젝트의
static경로를 우선적으로 삽입하는 경향을 보였다.
생성된 결과물은 다음과 같다. 전체 코드는 여기서 확인할 수 있다.
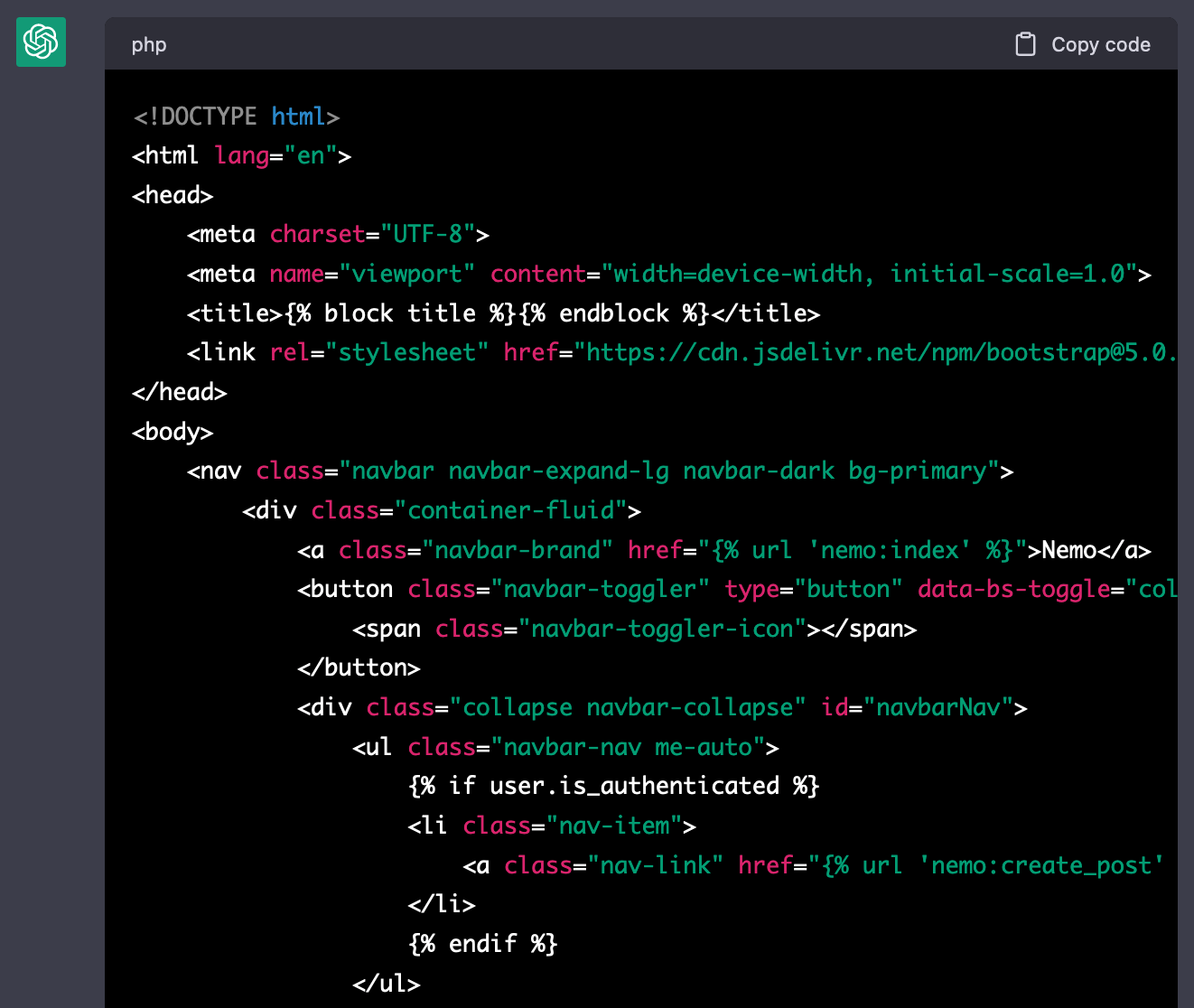
세부 템플릿 만들기
템플릿을 만들 때에는 지금까지 프롬프트로 입력되어 왔던 앱의 주요 기능(features), 모델(models), 뷰(views) 그리고 URL 패턴(URLs) 정보를 모두 참고해야 한다. 그런데 이 정도 단계까지 오면, 주고 받은 문답의 양이 단일 세션 안에서 기억 가능한 범위(약 3,000 단어)를 넘어서면서 그동안의 작업 맥락이 유실되기 시작한다.
맥락이 유실된 채로 코드가 생성되면 어떤 일이 일어날까? 인덱스 화면(index.html) 생성을 시도한 아래 이미지를 보자. 앞서 생성한 IndexView 뷰에서는 포스트 목록을 템플릿으로 넘길 때 posts라는 컨텍스트(context)를 사용했는데, 정작 템플릿을 생성할 때엔 이 정보를 기억하지 못하고 post_list라는 이름을 멋대로 지어냈다.
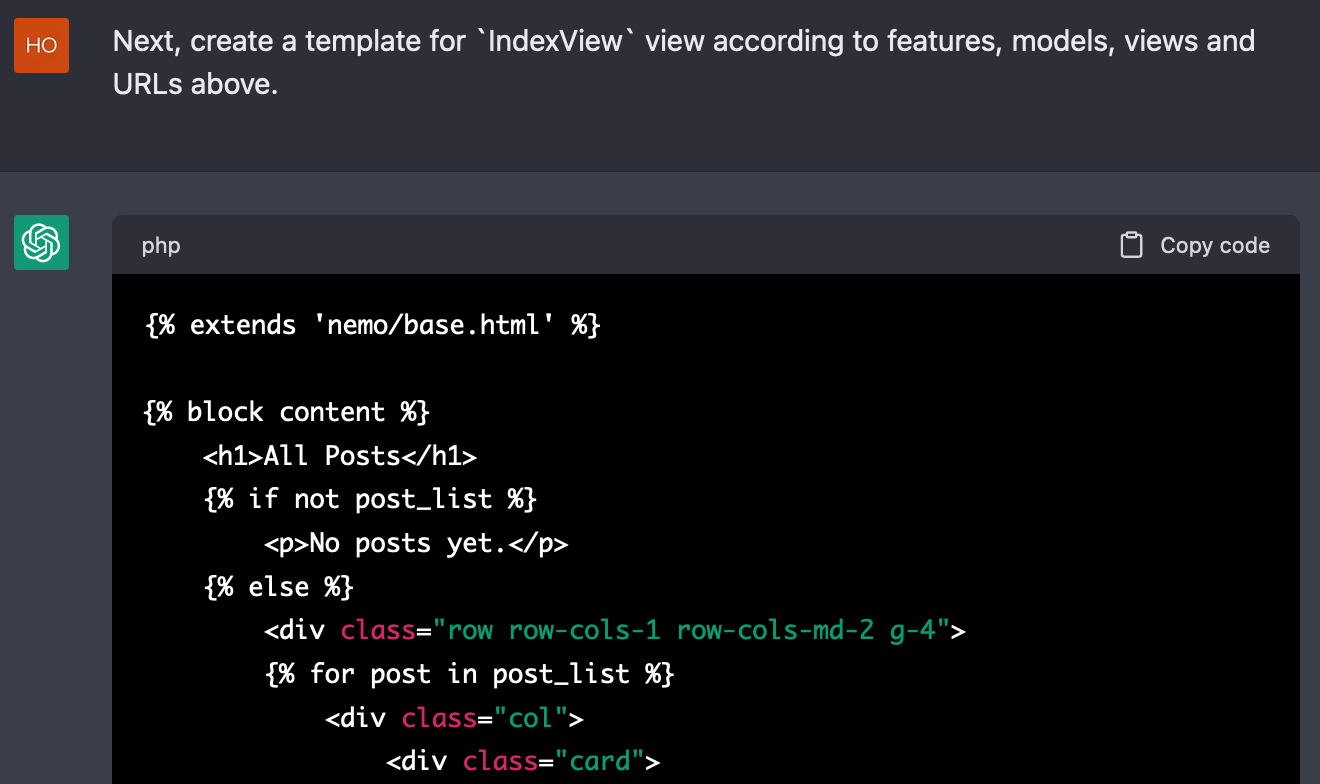
일단 유실된 맥락의 내용은 복구가 불가능하다. 어쩔 수 없이 필요한 내용을 추려서 새 프롬프트로 다시 채워주어야 한다. 이렇게 하여 수정한 인덱스 화면(index.html) 생성용 프롬프트는 다음과 같다. 과제 내용을 잊어먹은 친구에게 알려주듯 필요 정보를 간략하게 요약해서 다시 전달했다.
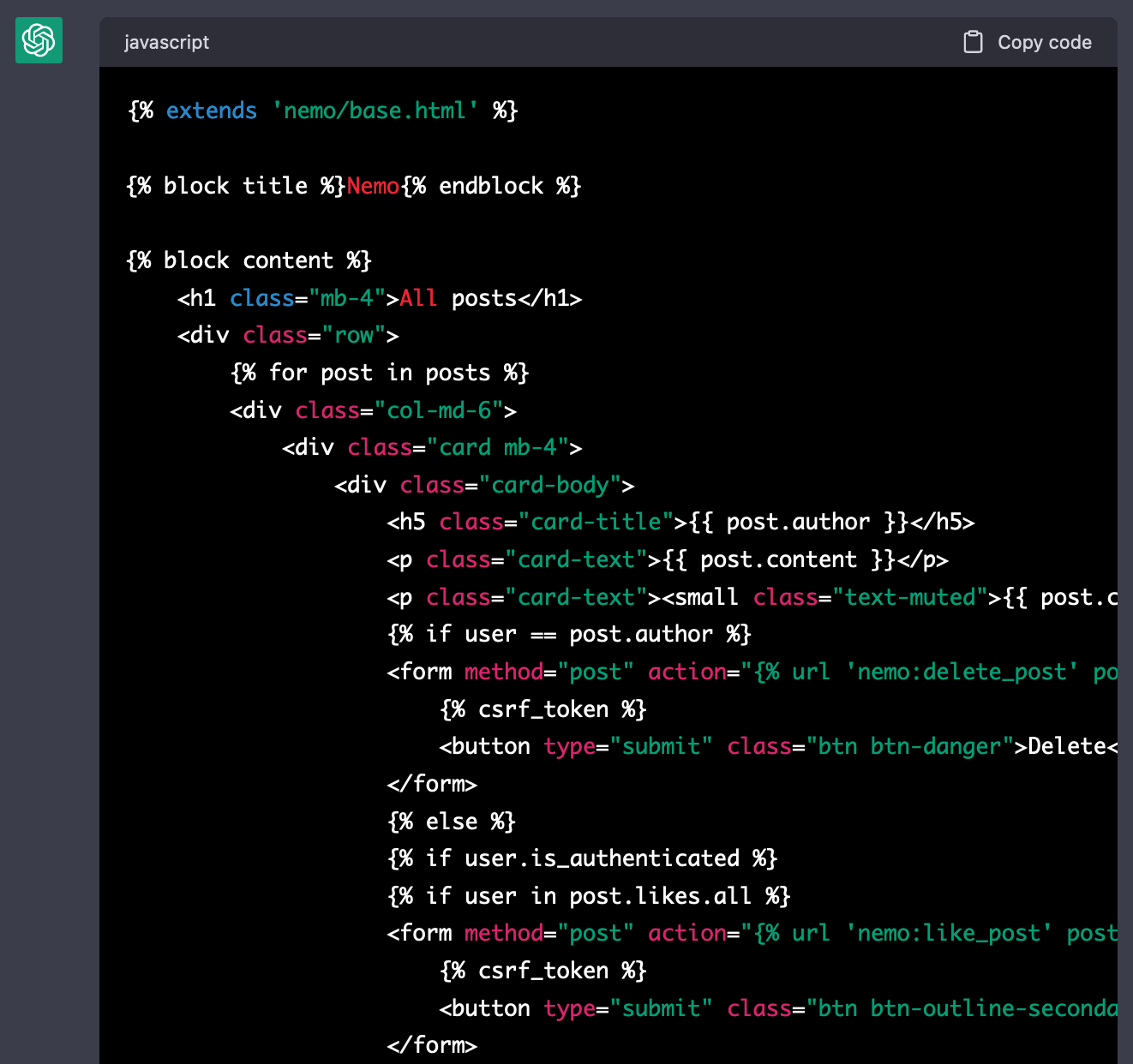
Next, create a template for `IndexView` view according to features, models, views and URLs above.
It'll list the whole posts(`posts`) in DB.
Each post(`post`) contains `content`, `author`, `created_at` and `likes`.
If user is the author, 'Delete' button must be appeared.
If user is not the author but logged user,
'Like' or 'Unlike' button must be appear.
그러자 놀랍게도 제대로 된 인덱스 화면용 템플릿이 생성되었다. 전체 코드는 여기서 볼 수 있다.
나머지 템플릿들은 코드 내용이 대체로 대동소이하므로 아래 프롬프트로 한 번에 생성했다. 다행히 URL 패턴 정보는 아직 유실되지 않은 상태여서 별 문제 없이 코드가 완성되었다.
Next, create templates for `RegisterView`, `LoginView`, `CreatePostView` and `DeletePostView`
according to views you created before.
For every form you must add an `action` attribute with proper URL paths you created before.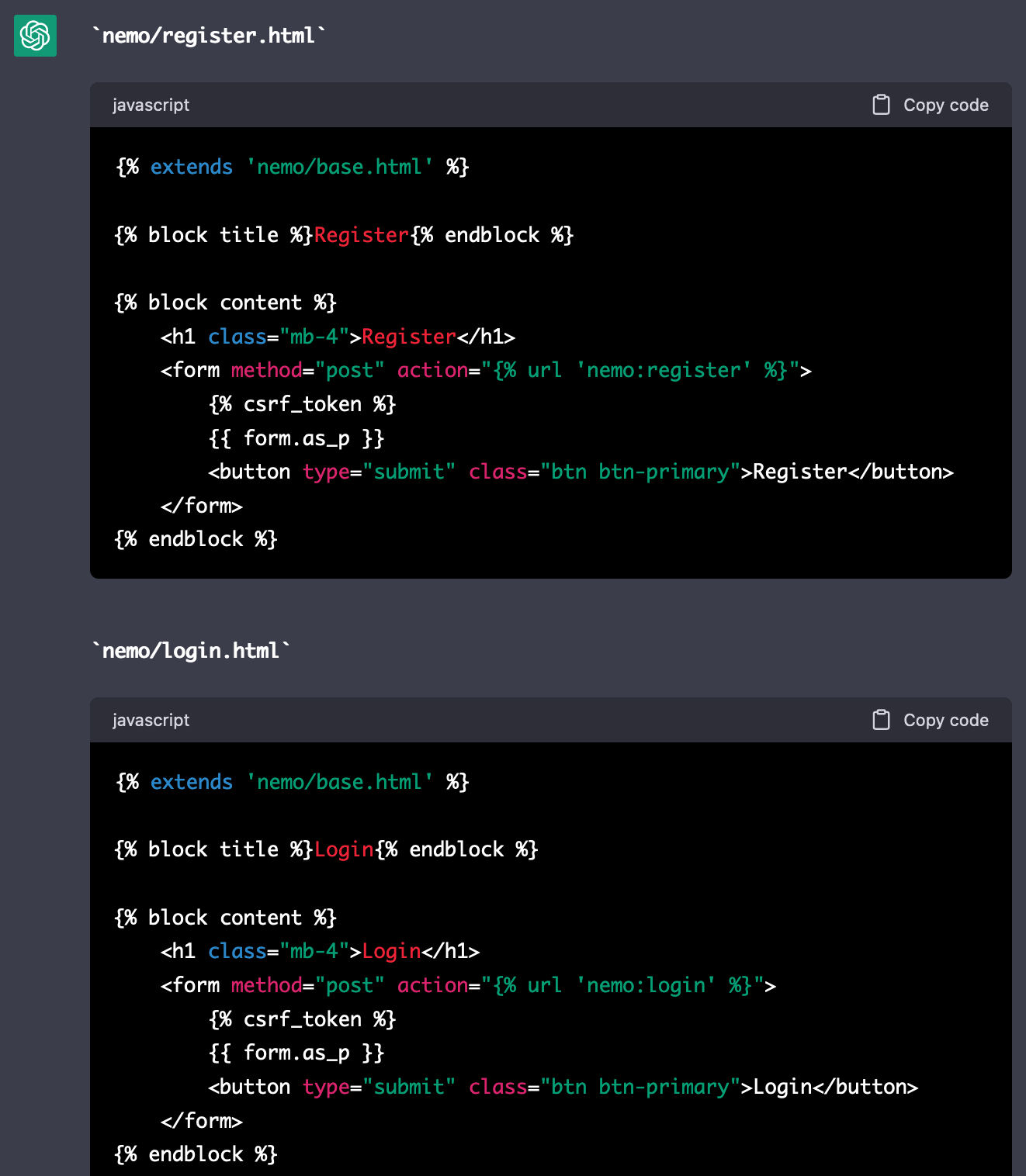
버그 수정하기
Django가 기본 제공하는 LoginView 클래스는 로그인 완료한 사용자를 account/profile/ 또는 프로젝트 settings.py의 LOGIN_REDIRECT_URL 변수에 지정된 경로로 이동시킨다. 만약 그 경로에 아무 것도 없다면 모든 사용자들이 로그인 할 때마다 404 Not Found 에러를 만나게 된다.
앞서 ChatGPT가 생성했던 로그인 화면용 뷰(View)의 코드는 다음과 같다. 이대로라면 "Nemo"에 로그인 할 때마다 위의 문제를 겪게 될 것이다.
class LoginView(LoginView):
template_name = 'nemo/login.html'
여기에 next_page 속성을 추가하여 로그인 완료시 index 화면으로 이동하도록 변경할 것이다. ChatGPT가 이 작업을 수행하도록 다음과 같이 입력했다.
Now let's back to the views you created before.
For `LoginView` view, I want to redirect users to `IndexView`
if the login process is completed.
Add `next_page` attribute to `LoginView` view below:
"""
class LoginView(LoginView):
template_name = 'nemo/login.html'
"""
결과는 아래와 같다.
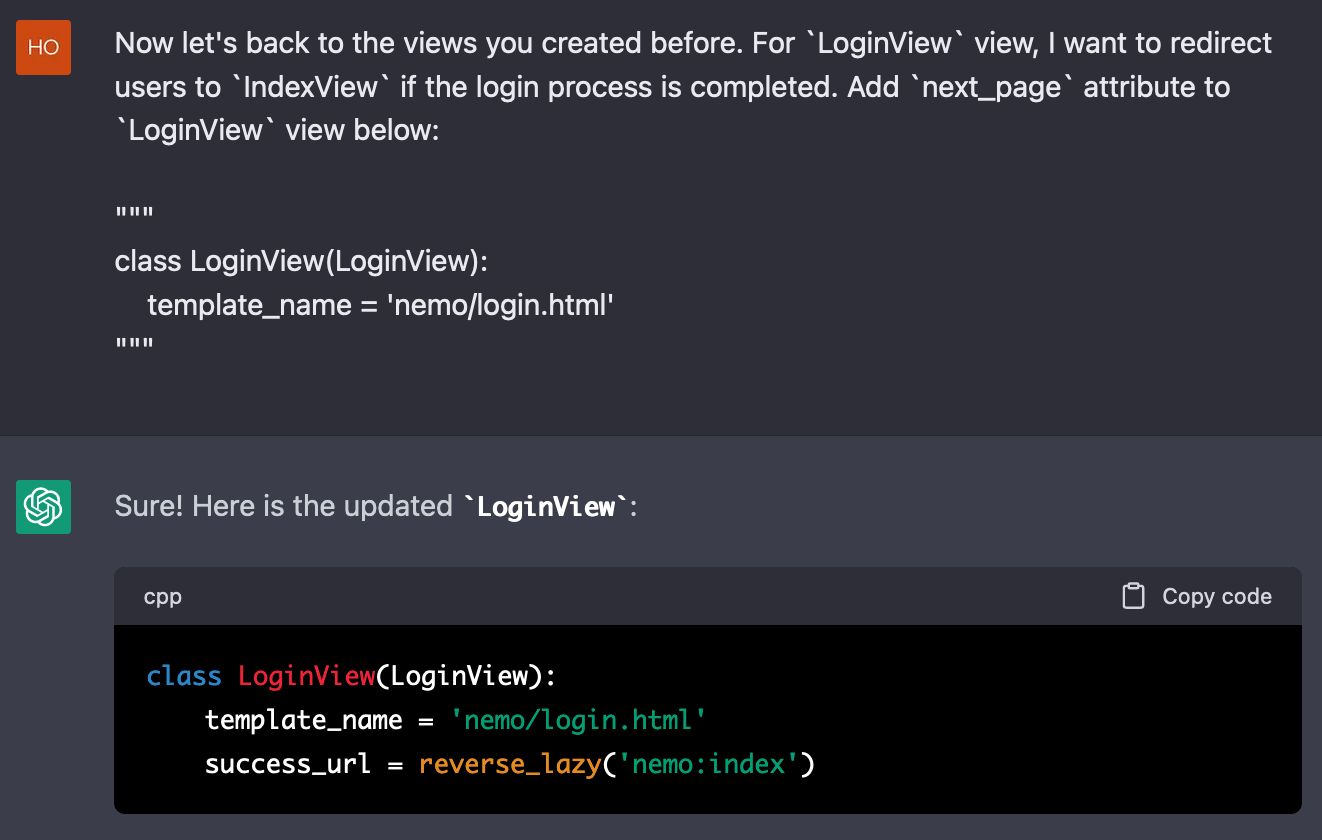
next_page 속성을 요청했는데 엉뚱한 이름의 속성이 대신 붙었다. 꼼꼼하게 지시한 내용도 곧잘 잊어버리거나 무시하는 모습이 정말 인간적이다. ChatGPT가 가진 또 하나의 인간적인 구석은, 문제를 지적하면 그 내용을 반영한 새 결과물을 내놓는다는 점이다. 이 역시 GPT와 같은 언어 모델이 가진 맥락 기억 능력 덕분에 가능한 일이다.
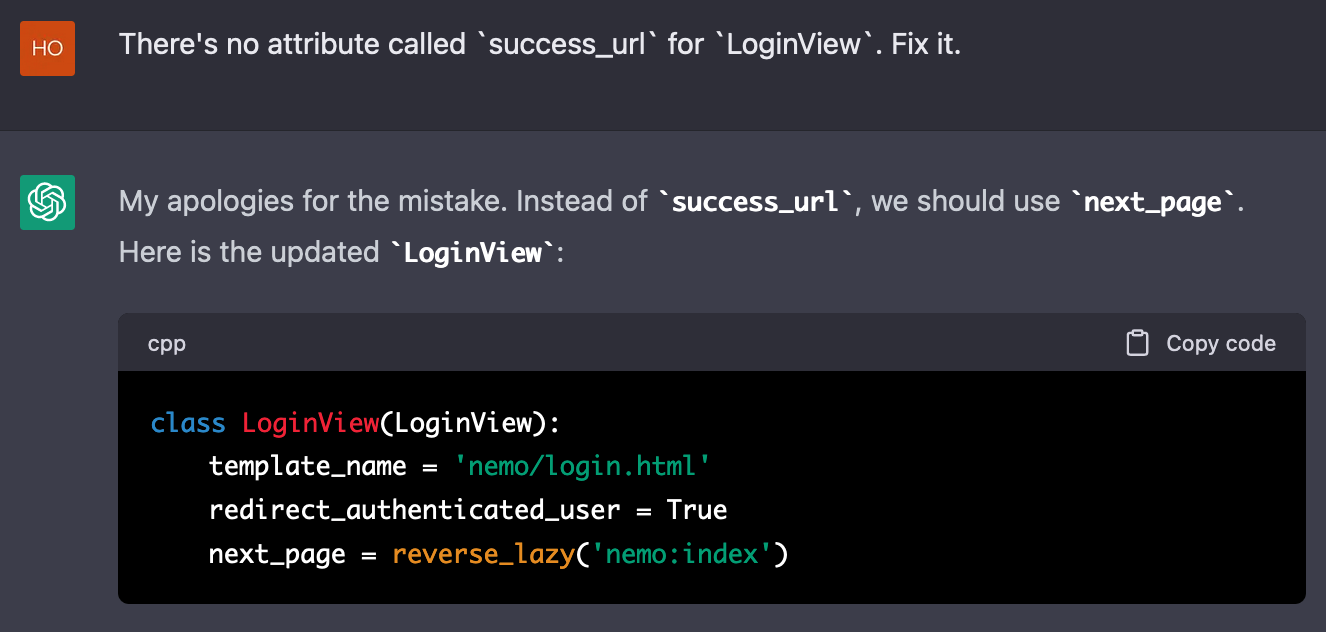
이번에는 next_page가 올바르게 삽입되었고, 이미 로그인 한 사용자가 로그인 화면에 접근할 경우를 고려한 redirect_authenticated_user = True까지 함께 추가되었다. 이로써 문제가 해결되었다.
제작한 웹 애플리케이션의 구동 결과
이렇게 만들어진 "Nemo" 앱을 실제로 구동시켜 보았다. 놀랍게도 의도했던 모든 기능이 온전하게 동작하는 것을 확인할 수 있었다. ChatGPT에서 채팅 만으로 실제 동작하는 웹 애플리케이션 코드를 완성한 것이다.
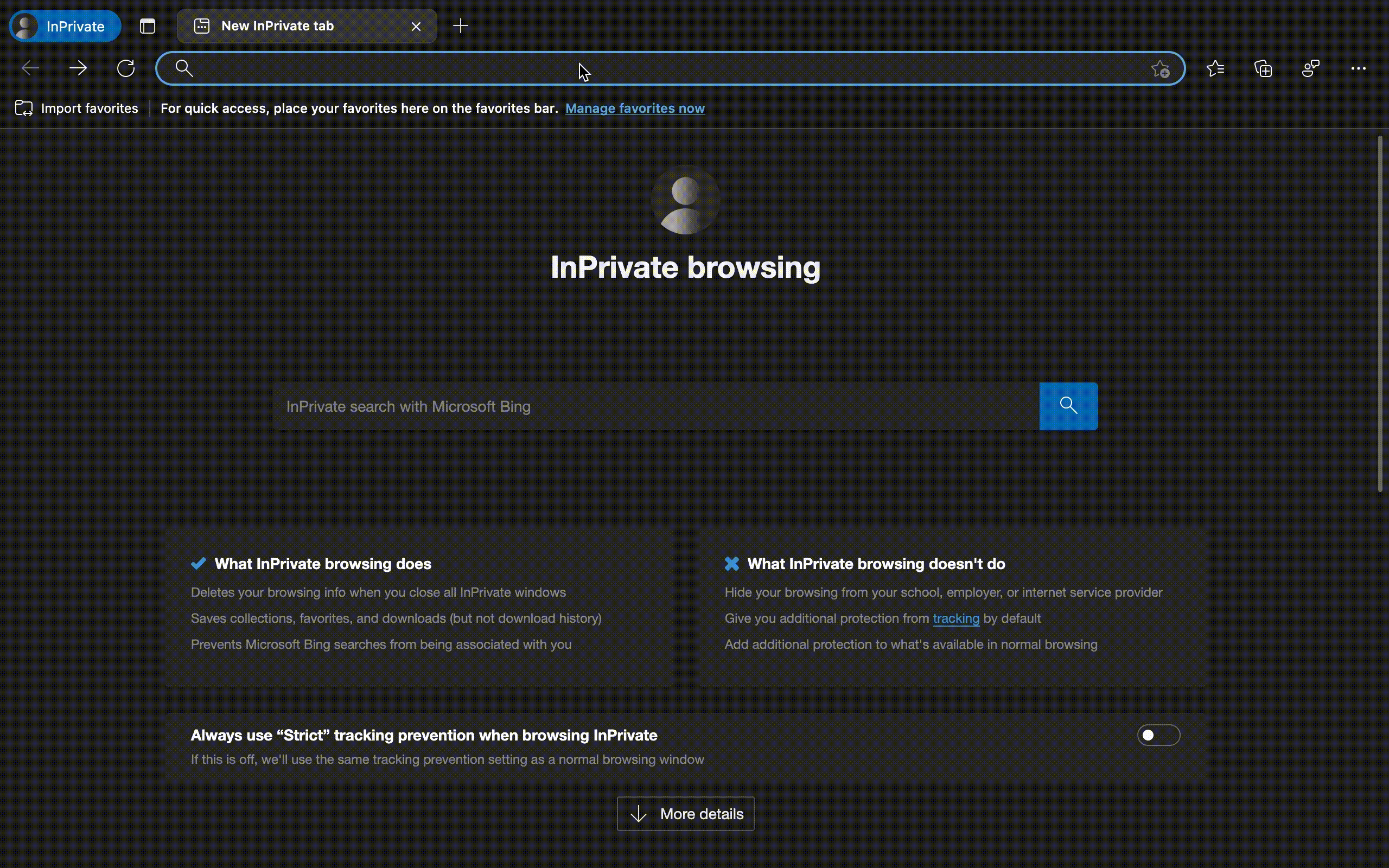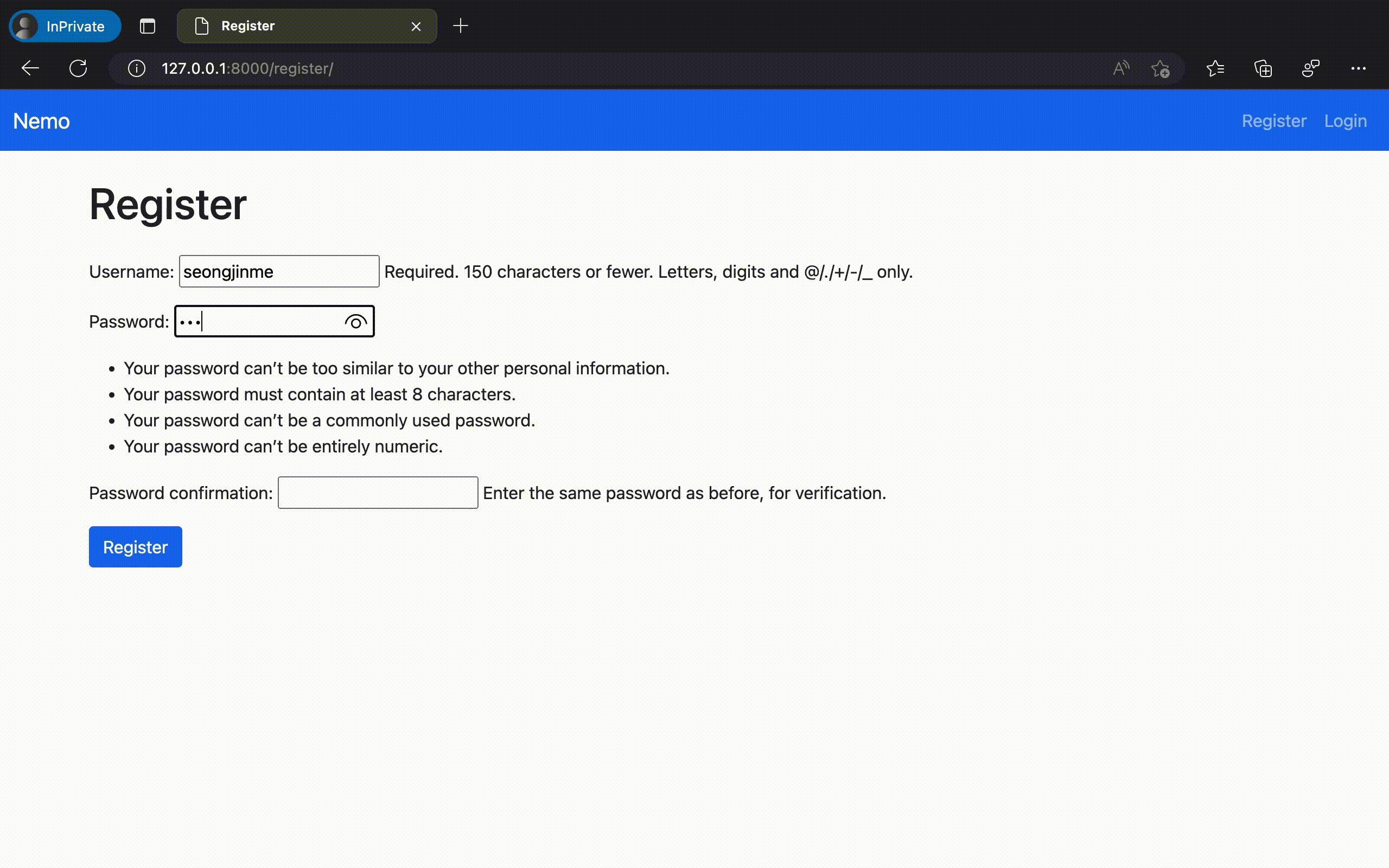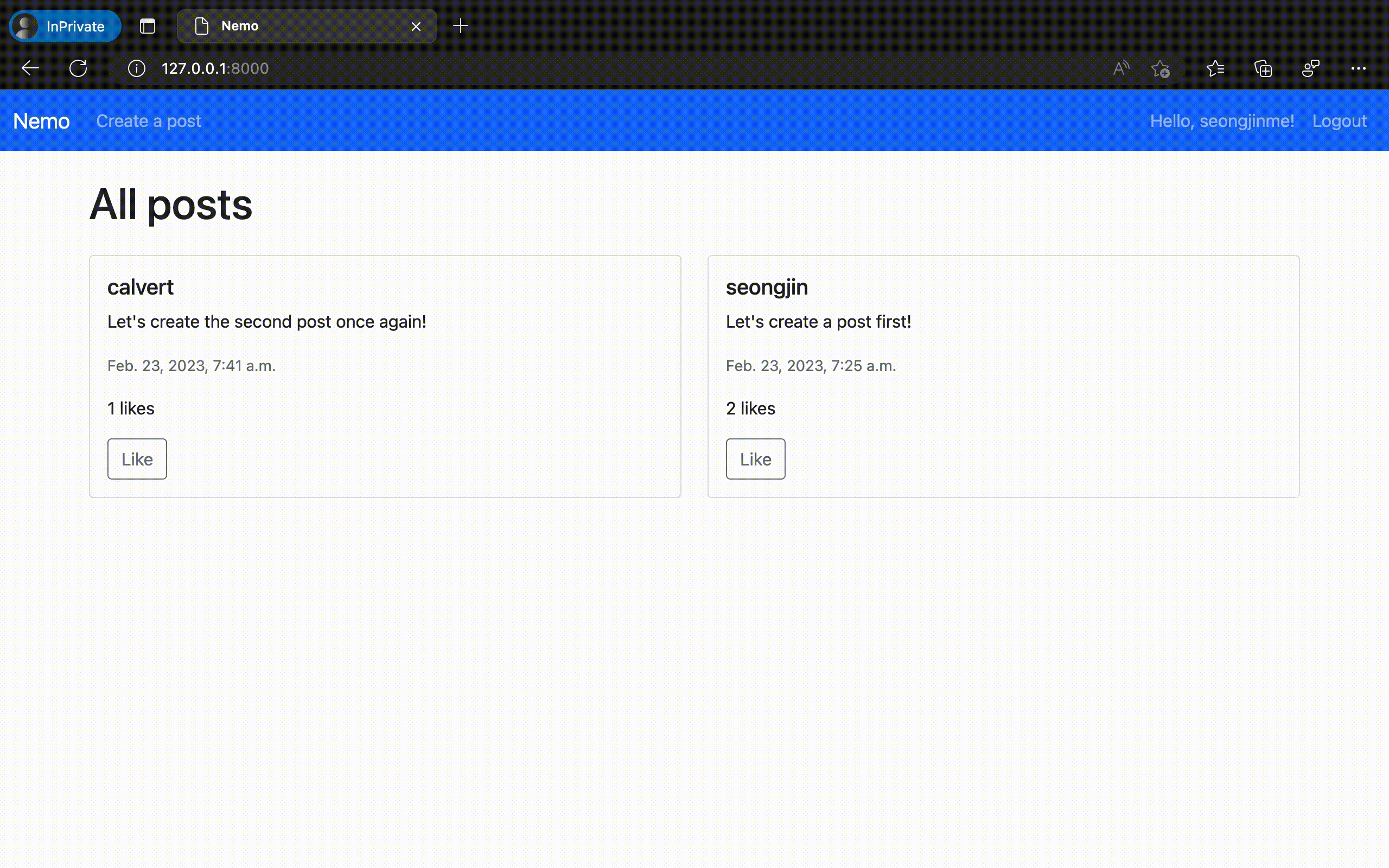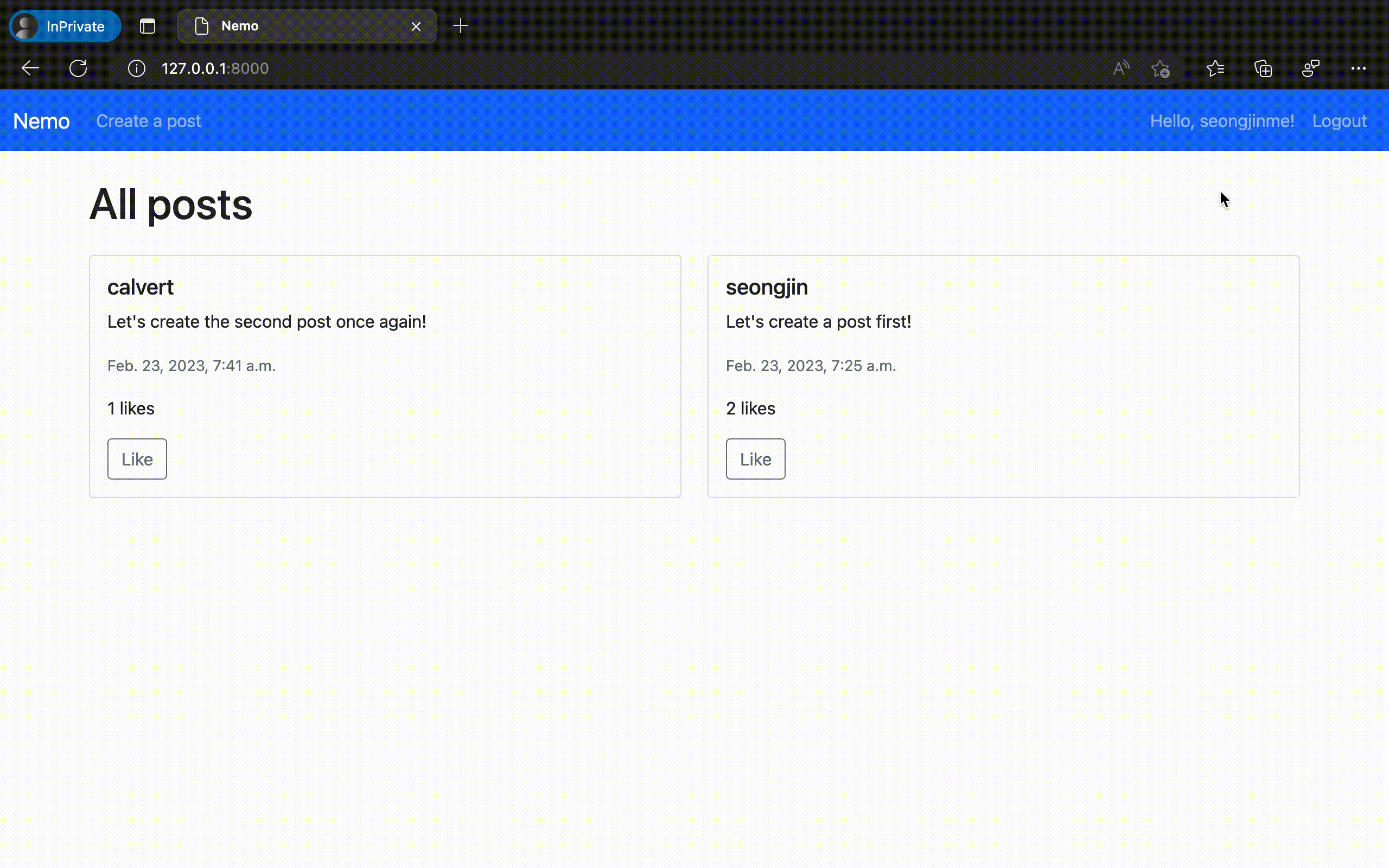
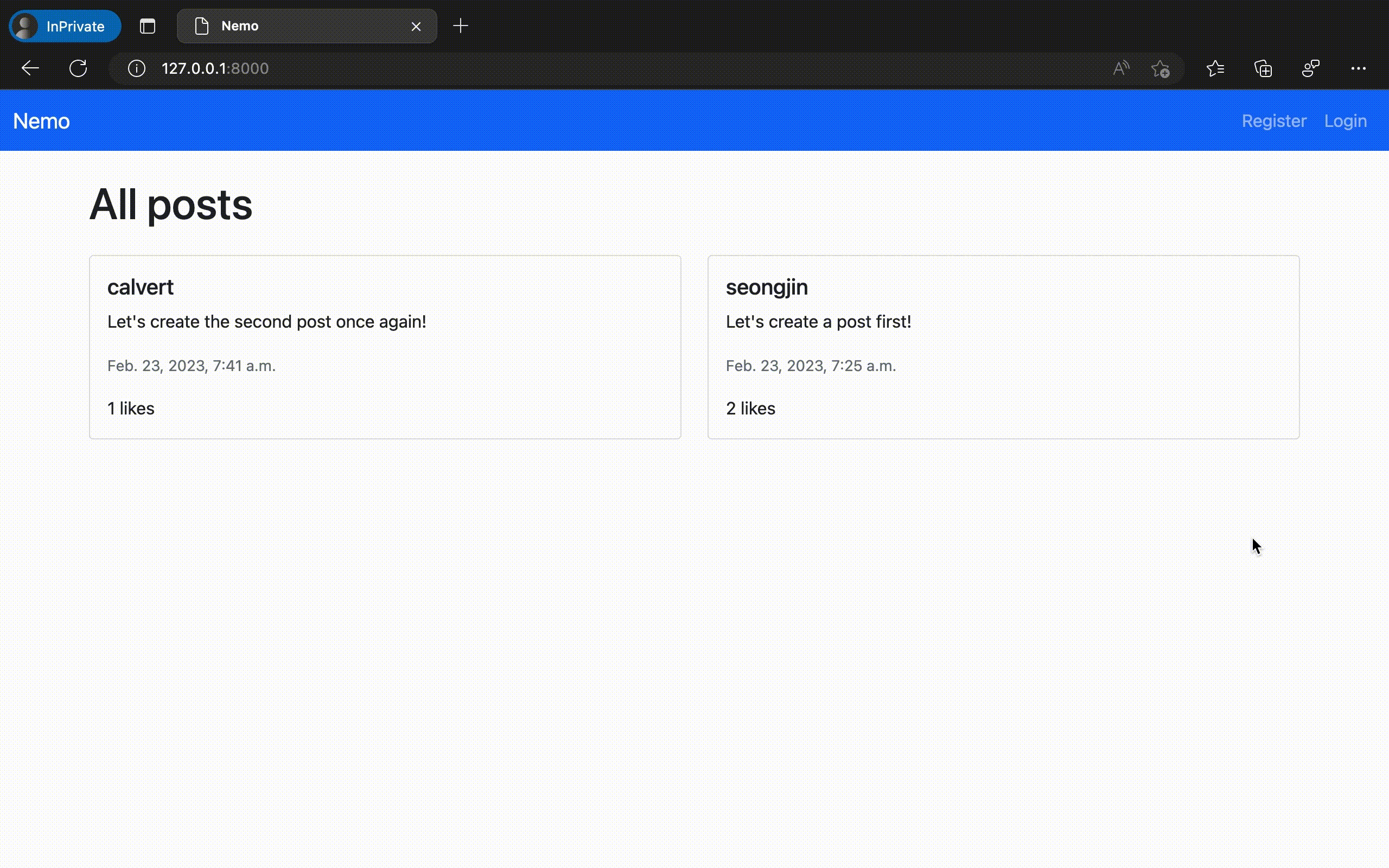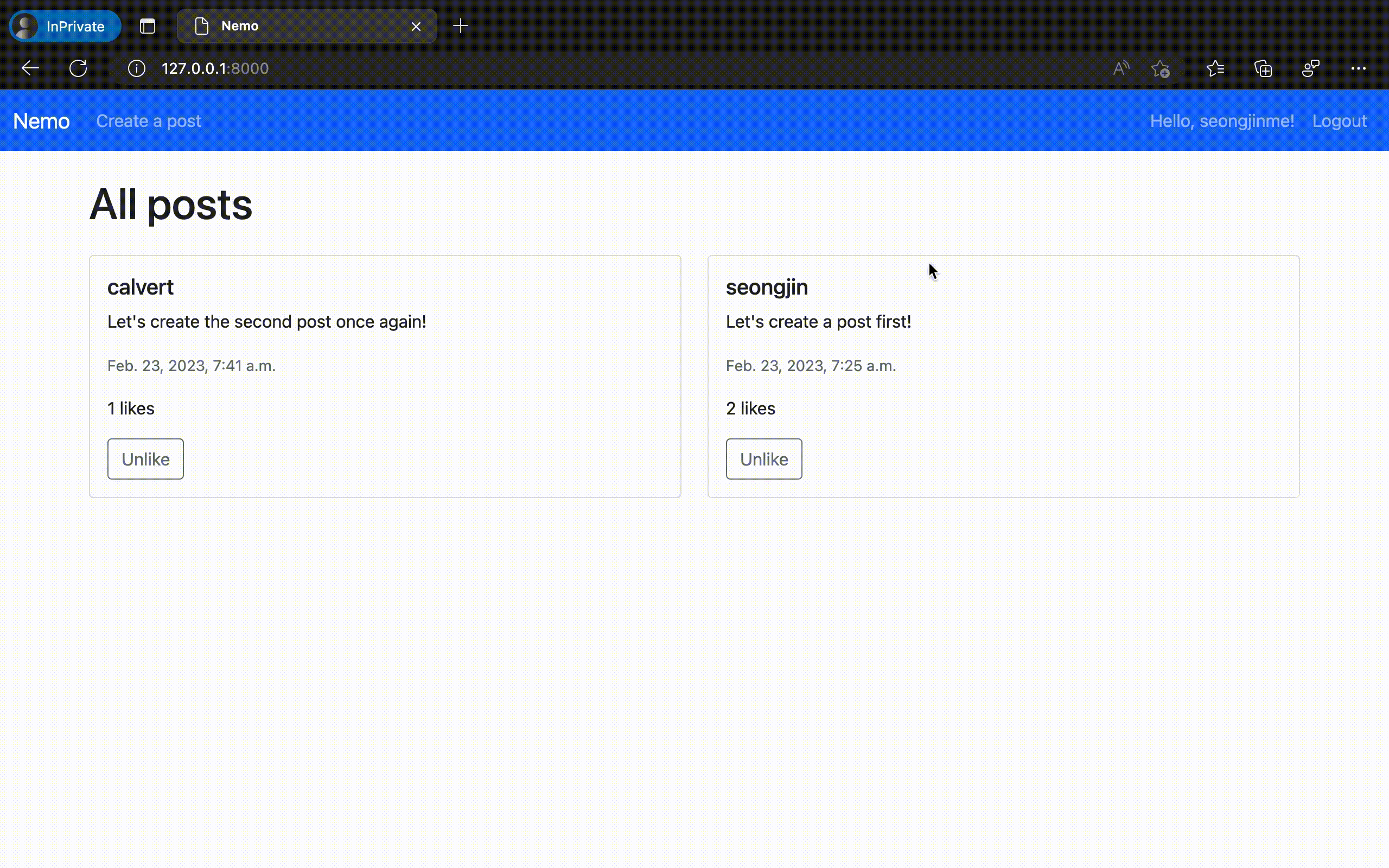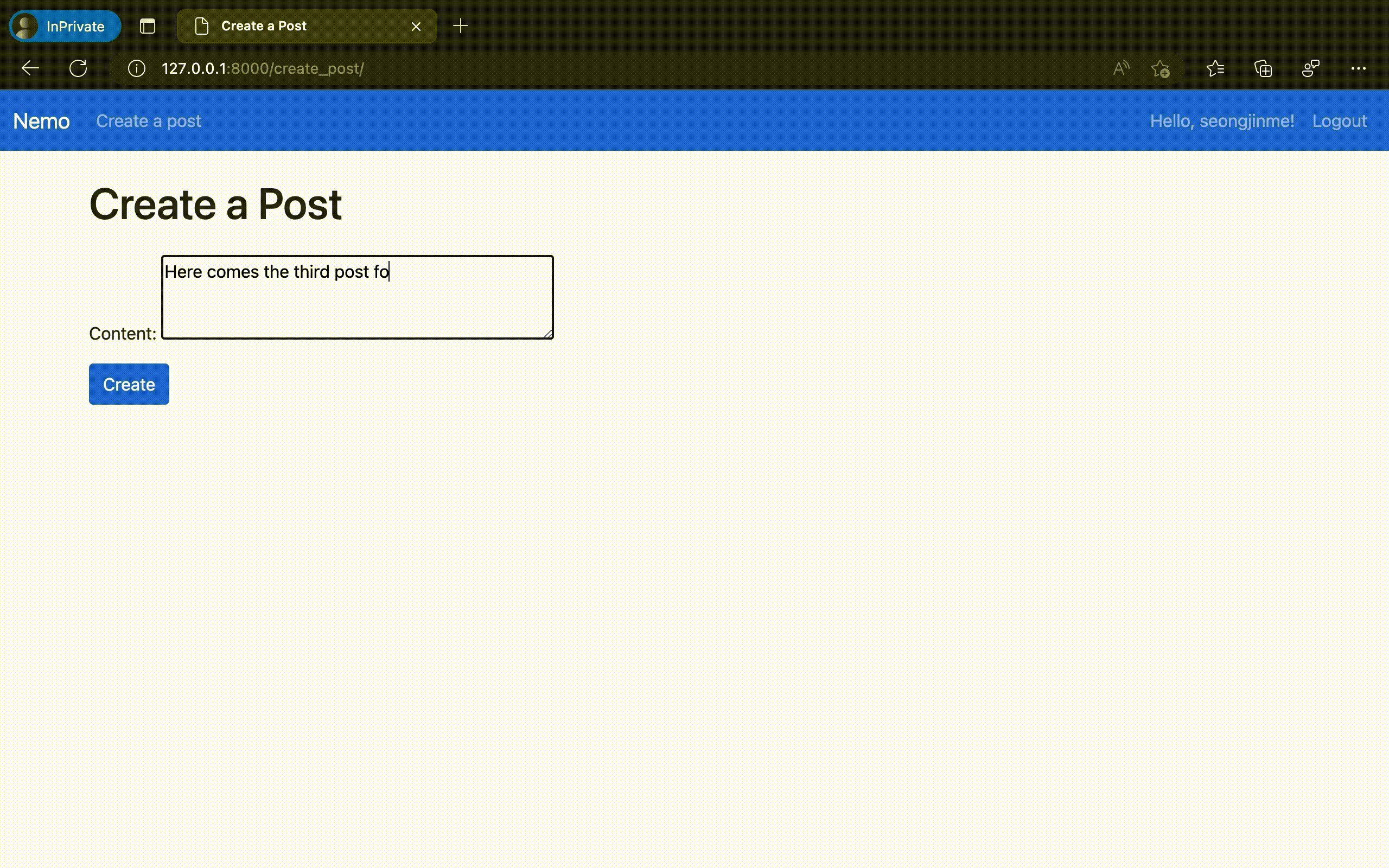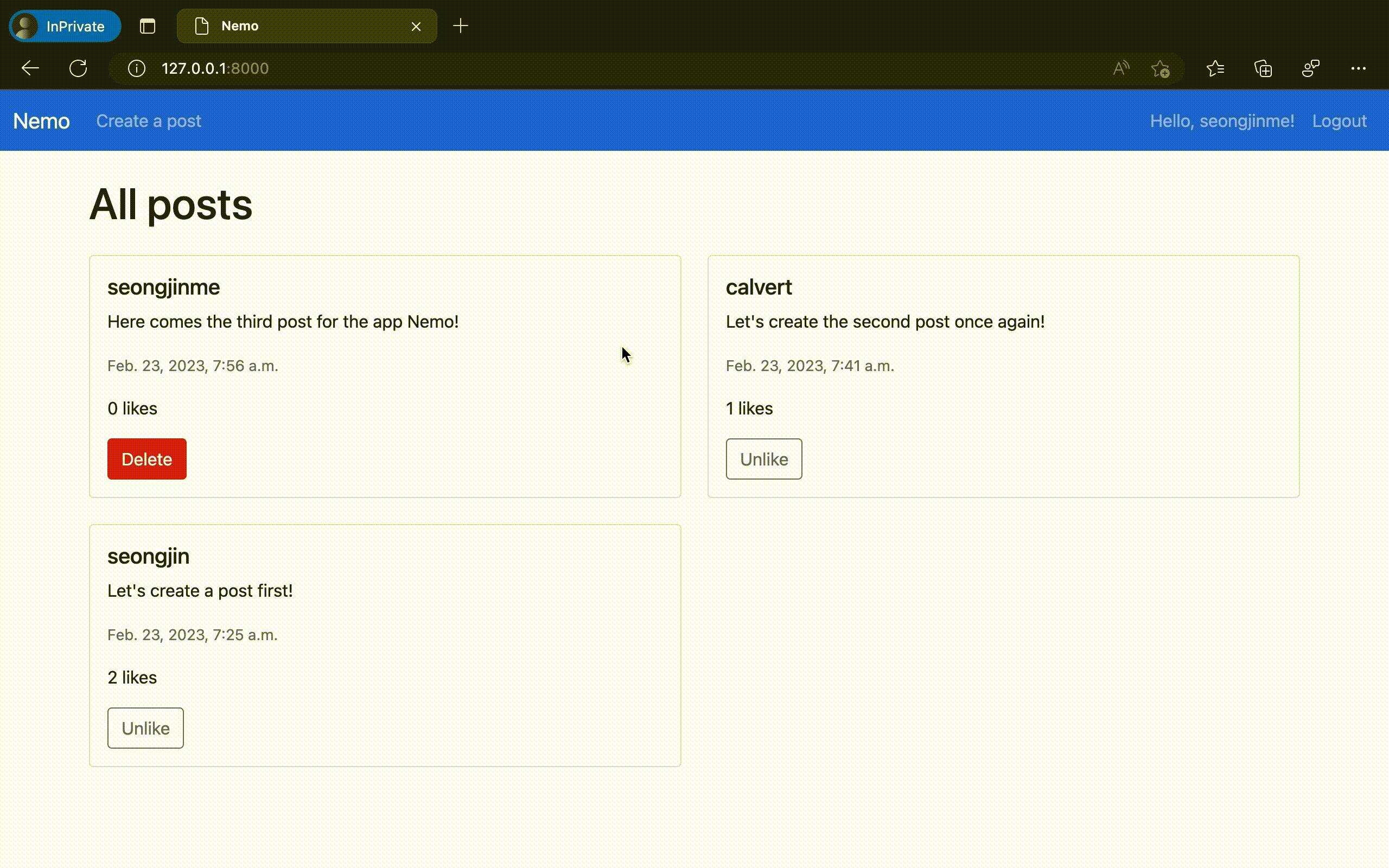
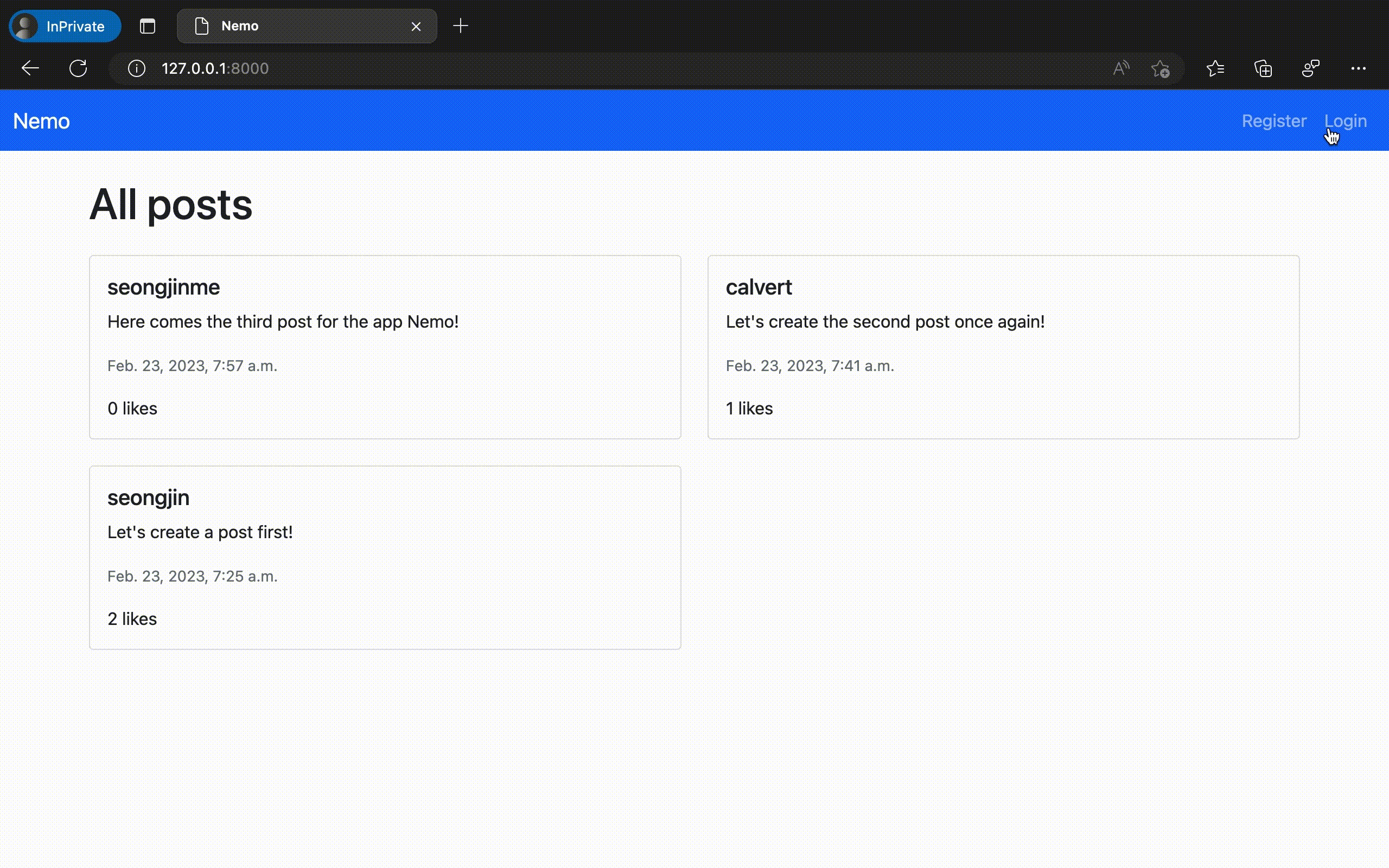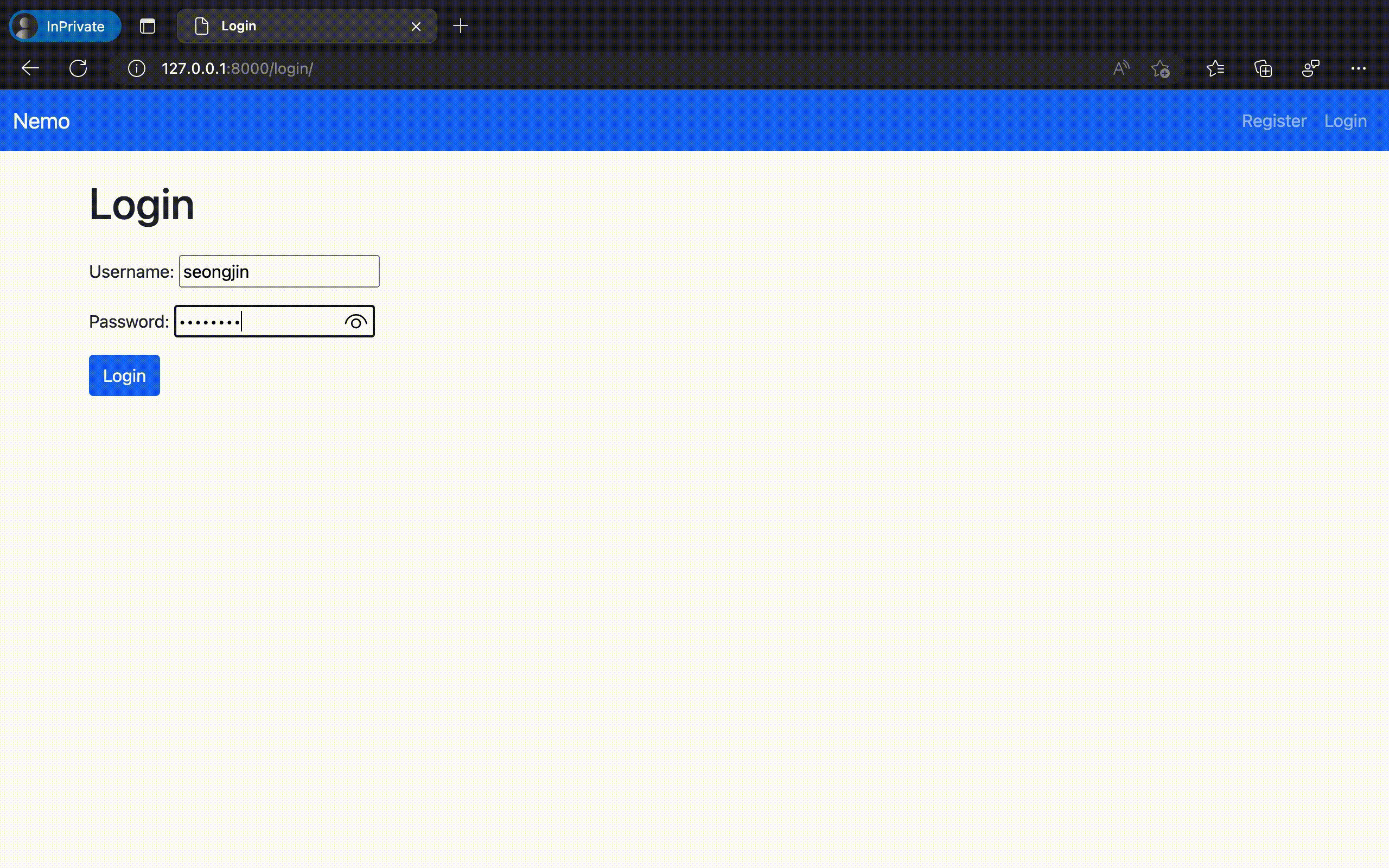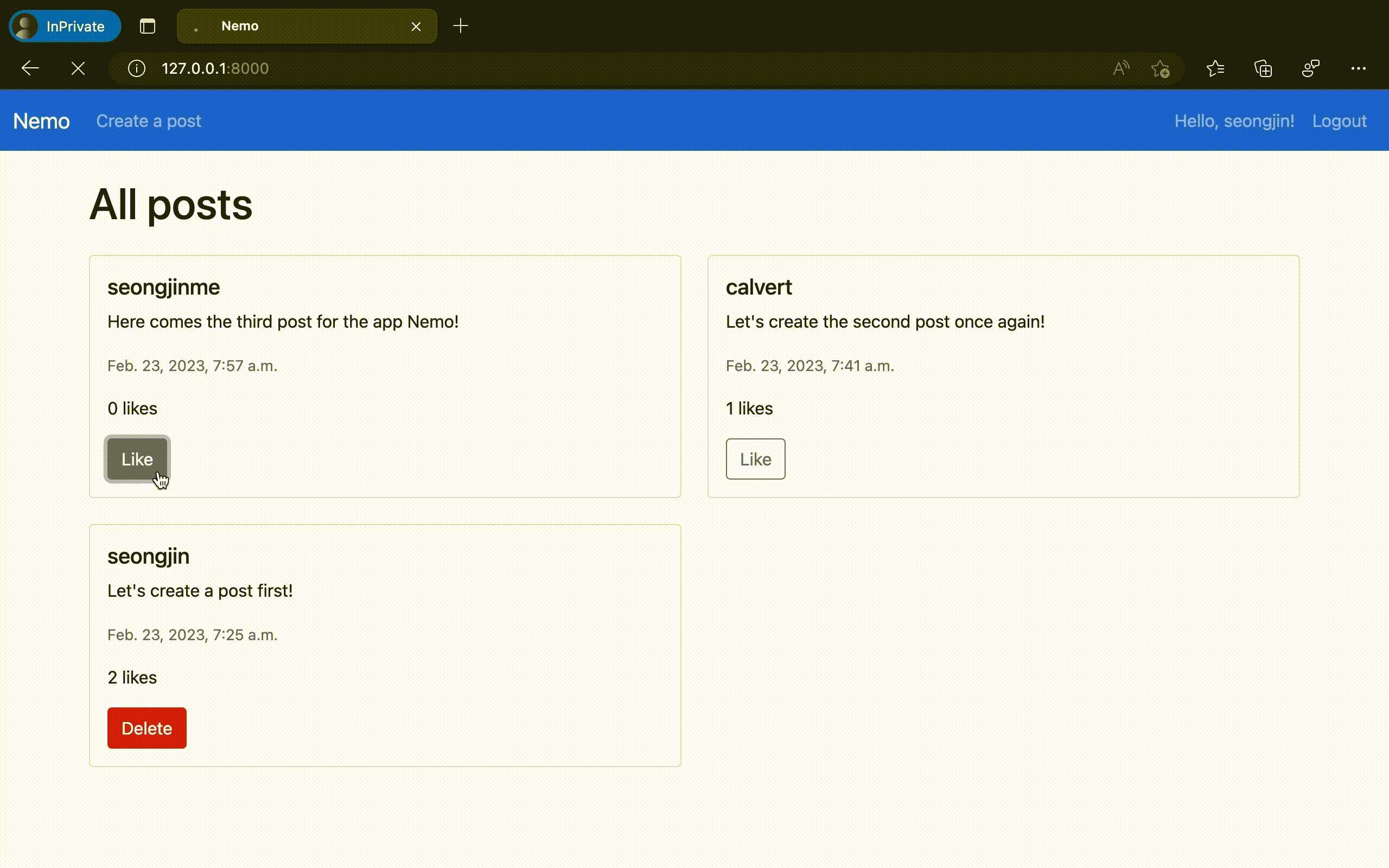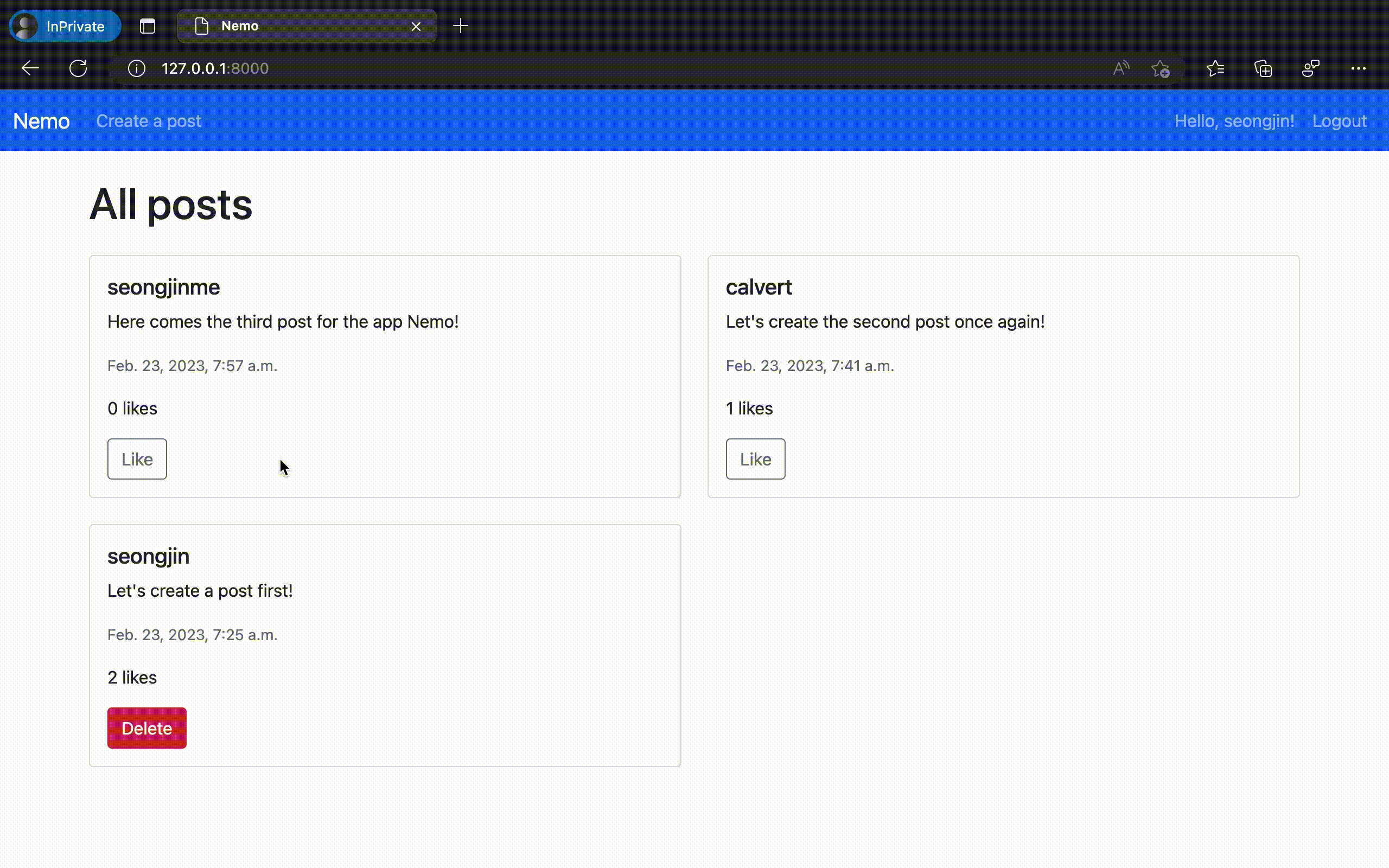
물론 이번에 만들어 낸 것은 오직 '가능 여부'만을 확인하기 위해 극단적으로 간소화 한 규격의 애플리케이션이다. 이 정도의 복잡도 만으로도 실제로는 수십 개의 대화 세션과 수만 단어 이상의 프롬프팅 테스트를 사전에 진행해야 했음을 밝혀둔다.
이번 실험이 남긴 시사점
이 실험은 "채팅 만으로 애플리케이션 개발이 가능한가?"라는 가벼운 호기심에서 시작되었다. 그러나 실험을 이어가는 과정에서 얻게 된 시사점은 그리 가볍지 않았다. 사실 이번 포스팅은 실험 내용 자체보단 이번에 얻은 시사점을 나름대로 정리하고자 쓰게 된 것이다.
프로덕션 환경에서도 ChatGPT로 앱을 만들 수 있을까?
2023년 2월 기준으로 프로덕션 환경에서 이런 작업은 거의 불가능하며, 설령 시도하더라도 결과물의 품질이 결코 좋지 못할 것이라는 게 내 의견이다.

대부분의 애플리케이션은 일정한 디자인 패턴에 따라 구조화된 코드 체계를 가지게 된다. 그런데 ChatGPT와 같은 생성 AI 서비스의 실질적 기능은 입력받은 프롬프트 다음에 올 내용을 확률적으로 추측하여 생성해주는 것에 불과하다. 이러한 생성물이 의도한 체계에 적합한 형태를 유지하도록 강제하려면, 결국 그 구조에 대한 정보를 GPT와 같은 언어 모델에게 계속적으로 주입해야 한다. ChatGPT의 경우를 예시로 들자면, 채팅을 통해 주고 받는 모든 문답에 대한 일정한 맥락(Context)이 어떠한 상황에서도 유실 없이 유지되어야 하는 것이다.
그런데 앞서 언급했듯이, ChatGPT의 기반이 되는 언어 모델에서는 일정하게 기억 가능한 맥락의 범위가 제한되어 있다. 서로 다른 세션 간에는 어떠한 맥락도 전달되지 않으며, 오직 하나의 세션 안에서만 작업 맥락이 유지된다는 제약도 있다. 게다가 생성되는 응답의 분량도 현재로서는 상당히 제한되어 있다. 그러니 작업이 이어질수록 맥락은 휘발되고 품질은 떨어진다. 이러한 제한점들은 고도의 추상화와 기억 능력이 요구되는 복잡한 작업을 지속하기 어렵게 만든다.
또한 GPT 언어 모델의 결과물 생성 원리는 확률론적 모델(probabilistic model)에 기반해 있다. 이는 달리 말하면, 매번 같은 프롬프트를 입력하더라도 그것이 100% 똑같은 결과물의 생성을 보장하지 않는다는 뜻도 된다. 당장 위의 실험 과정에서 소개한 프롬프트를 ChatGPT에 똑같이 입력한다고 해도 내가 얻은 것과 동일한 코드를 얻는다는 보장이 없다. 이러한 ChatGPT의 특성은 결국 생성 결과물의 일관성에 부정적인 영향을 미친다. 작은 결함이 큰 손해로 이어질 수 있는 소프트웨어 개발 영역에서 이는 무시할 수 없는 문제다.
과연 앞으로도 계속 불가능할까?
하지만 일정 분량을 넘어가는 맥락 데이터의 유실, 응답 길이의 제한과 같은 문제들은 근본적으로 현존하는 GPT 등 언어 모델들의 스펙상 한계로 인한 일시적인 이슈에 가깝다. 약 4,000 토큰 수준에 불과한 현재의 기억 능력이 앞으로 나오게 될 GPT-4나 그 이후에도 그대로 유지되리라 믿는 사람은 없을 것이다.
ChatGPT의 개발사인 OpenAI는 이미 최신 GPT 언어 모델을 기업 등 고객 전용 상품으로 가공한 Foundry 플랫폼을 지난 2월 17일에 조용히 공개했다. 이 플랫폼이 내세우는 핵심 경쟁력은 두 가지다. 최대 8배(32,000 토큰)까지 확장된 맥락(Context) 기억 범위, 그리고 더욱 정교하게 파인 튜닝된 최신 AI 모델의 제공이다. 32,000 토큰은 영문 기준으로 약 13만 자 가량이며, 이를 텍스트로 변환하면 130kB 분량이 된다. 이처럼 기억의 용량, 맥락의 추론 능력이 더욱 발전된 미래의 언어 모델은 훗날 인간을 상대로 한 것과 비슷하거나 더 나은 협업 경험을 제공하게 될 수도 있다.
생성 인공지능이 앞으로 내 실무에 어떤 영향을 미치게 될까?
이번 실험에 사용한 ChatGPT는 거대 언어 모델(LLM) 기반 기술의 대중화를 위해 여러 용도에 범용성을 가지도록 만든 서비스라는 점을 유념해야 한다. 특정 목적과 환경에 따라 맞춤형으로 엔지니어링 된 전용 언어 모델이 실무에 도입되었을 때의 파급력은 ChatGPT 등 범용 서비스의 경우와는 질적으로 다를 것이다.
웹 기반 제품을 전문적으로 개발하는 기업의 업무 환경을 예시로 가정해보자. 회사의 각종 제품들과 그에 포함된 레거시 코드, 프레임워크, 코드 컨벤션, 개발/운영 환경의 인프라 구성 정보 등을 맞춤형으로 학습시킨 AI 솔루션이 사내 개발 업무 도구로 쓰이게 된다면? 기존의 ChatGPT를 이용할 때와 같이 복잡한 맥락 정보를 매번 프롬프트로 입력할 필요가 없어질 것이다. 동료와 대화하듯 자연스러운 채팅 입력 만으로 각종 코드 생성 및 사무 작업이 가능해질 수 있다.
물론 이렇게 생성된 결과물의 세밀한 조정과 품질 검증, 그리고 제품 전반에 대한 설계 및 개선작업에는 사람의 손길이 필요하다. 그러나 핵심적인 개발 업무 수행을 위해 그동안 부수적으로 반복해야 했던 단순 작업들은 상당 부분 인공지능과 프롬프트의 역할로 넘어가게 될 것이다. 이렇게 변화된 환경에서는 결국 프롬프트를 어떻게 다루느냐가 실무 효율을 크게 좌우할 수 있다. 이것이 지난 글에서 프롬프트 엔지니어링의 중요성을 강조한 이유다.