GPT 언어 모델에서 생성 데이터를 JSON 형태로 주고 받게 해주는 Function Calling 살펴보기
그동안 ChatGPT 등 GPT 기반 서비스에서 JSON 처럼 규격화 된 응답을 얻어내려면 많은 수고를 감수해야 했다. 최근에 OpenAI가 공개한 Function Calling은 이러한 불편 없이 API 호출 만으로 JSON 데이터를 얻어낸 뒤, 백엔드에서 원하는 함수를 실행하게 해준다. 그 방법을 예시와 함께 알아보도록 하자.

GPT와 같은 거대 언어 모델(LLM)과 애플리케이션의 결합을 시도해 본 엔지니어라면 생성 데이터의 양식 문제로 머리 아팠던 경험이 한 번쯤은 있을 것이다. 자연어로 장황하게 쓰인 텍스트가 아닌, JSON 처럼 규격화 된 응답을 언어 모델로부터 받아내려면 각종 프롬프트 엔지니어링과 잔기술을 동원해야 했다. 지난 KinoQuizAI 프로젝트에서 가장 고생했던 지점이 바로 GPT로 생성한 데이터 양식의 일관성 유지였다.
최근에 OpenAI가 새로 발표한 Function Calling이 이러한 불편을 크게 해소시켰다. 생성된 데이터를 별도의 프롬프트 엔지니어링 없이 사용자가 지정한 JSON 형태로 받아낼 수 있게 된 것이다. 또한 이렇게 생성된 JSON 데이터를 특정 백엔드 함수의 인자(argument)로 넘기면서 해당 함수를 자동으로 호출하는 일도 가능해졌다.
이번 글에서는 GPT 언어 모델에서 새롭게 제공하는 Function Calling 기능을 살펴보기로 한다.
Function Calling 소개
Function Calling은 2023년 6월 기준으로 OpenAI의 gpt-4-0613과 gpt-3.5-turbo-0613 모델에서 지원한다. Chat Completion API에서만 제공되며, 아래에 소개할 두 개의 신규 파라미터(parameter)를 통해 구현된다.
functions: GPT 언어 모델을 통해 사용할 함수 정보를 리스트 형태로 입력한다. 여기에는 함수의 이름(name), 설명(description), 그리고 함수 실행에 필요한 JSON 데이터 스키마 형태의 인자 정보(parameter)가 포함된다.function_call: 1번 항목에 포함된 함수 가운데, GPT가 응답 데이터를 보낼 때 사용자 측에서 강제로 실행시킬 함수를 지정한다. 어떤 함수에 대한 실행을 요청할지 GPT가 스스로 결정하게 하거나(auto), 반대로 함수 실행 자체를 막을 수도 있다(none). 기본값은auto다.
여기서 유의할 점이 있다. 이것은 GPT가 직접 함수를 동작시키도록 만드는 도구가 아니다. 실제 함수의 실행과 결과 처리는 여전히 사용자의 몫이다. GPT는 사용자 측에서 어떤 함수를 실행하고자 할 때, 그 실행에 필요한 인자(argument)를 JSON 형태로 생성하여 준 뒤 해당 함수가 실행될 수 있도록 신호를 보내는 역할까지만 담당한다.
즉, Function Calling은 GPT를 매개로 하여 서로 다른 애플리케이션 또는 API 간 통신을 구현할 때 그 과정을 간편하게 만들어주는 기능으로 보는 것이 바람직하다.
GPT 언어 모델에서의 JSON 응답 구현 사례
Function Calling을 통한 JSON 응답 구현 사례를 살펴보자. 여기서는 지난 글에서 소개했던 KinoQuizAI 앱을 예시로 사용할 것이다.
우선 OpenAI API로부터 응답을 호출하는 기존의 코드를 먼저 들여다 보자. messages를 통해 프롬프트를 전송한 뒤 응답 데이터를 수신받는 간단한 구조로 되어 있다.
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": "Suppose you are an examiner in the movie lecture class."
},
{
"role": "user",
"content": prompt
}
],
temperature=parameters["temperature"],
top_p=parameters["top_p"],
frequency_penalty=parameters["frequency_penalty"],
presence_penalty=parameters["presence_penalty"],
max_tokens=parameters["max_tokens"]
)
return response["choices"][0]["message"]["content"].strip()
위의 코드를 통해 들어오는 생성 데이터는 오직 문자열(string)만 포함하고 있다. 여기서는 독자의 편의를 위해 임의로 줄바꿈을 추가했다.
In the movie "Inception", what is the name of the device
that allows people to enter and share dreams?
(A) The Dreamcatcher
(B) The PASIV Device
(C) The Mind Explorer
(D) The Dream Weaver
B
The PASIV (Portable Automated Somnacin IntraVenous)
Device is a briefcase-like machine used by Cobb
and his team to enter and share dreams.
It's designed to administer a sedative called somnacin,
which puts all users into a synchronized sleep state,
allowing them to connect with one another
in a shared dream world.
https://www.imdb.com/title/tt1375666/
사람이 읽기엔 편하지만, 이대로라면 이걸 데이터 항목 별로 다시 전처리 하기 위해 많은 작업이 소요될 것이다. 이제 이 문제를 해결해보자.
생성 데이터 양식을 JSON 스키마로 표현하기
먼저 필요한 것은 내가 생성받고자 하는 데이터의 JSON 스키마다. 지난 글에서 소개한 ERD에서 Quiz에 해당하는 내용을 살펴보자.
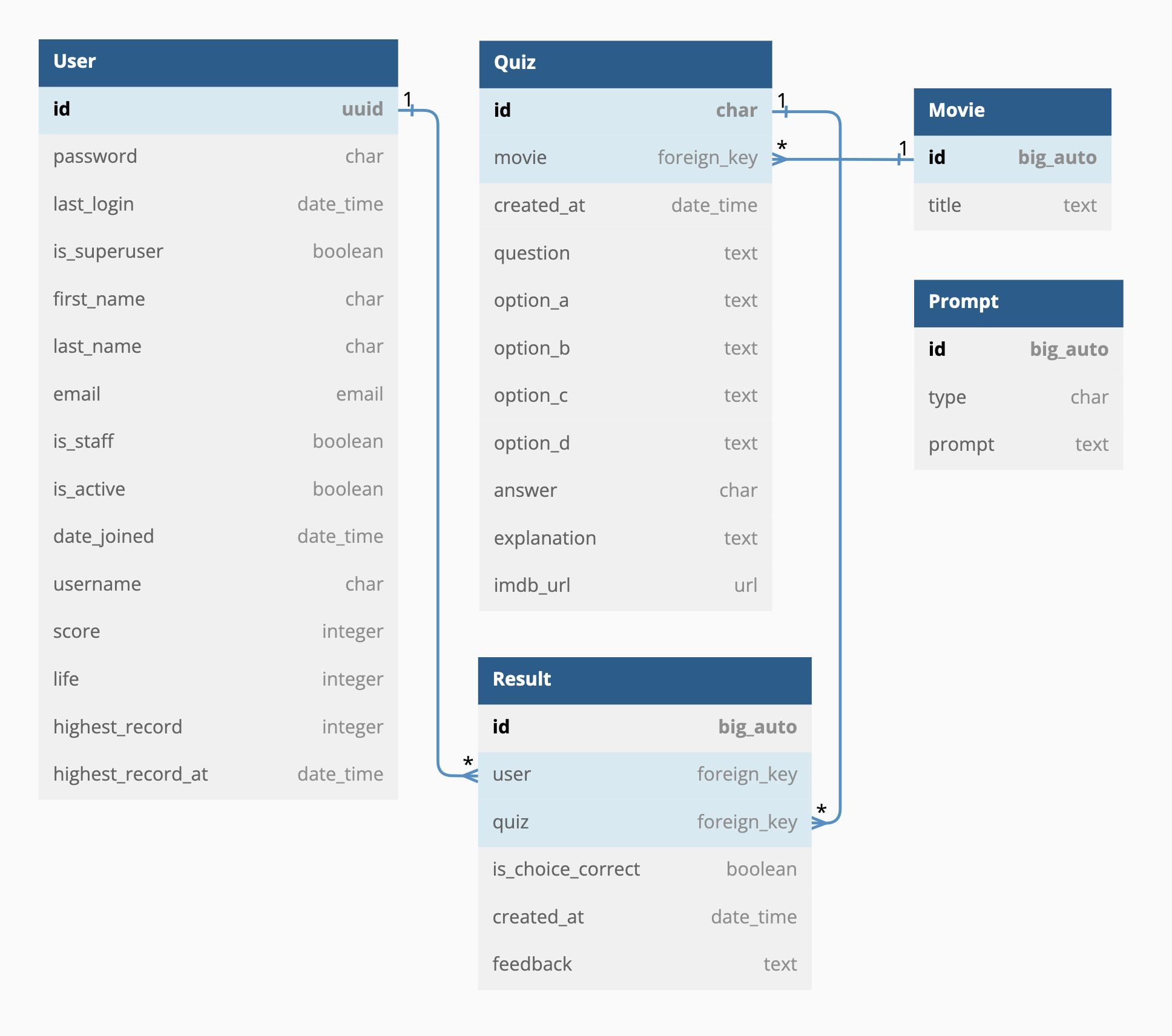
위 내용을 참고하여 스키마(quiz_data_schema)를 아래와 같이 작성했다.
quiz_data_schema = {
"type": "object",
"properties": {
"question": {
"type": "string",
"description": "The question of the quiz. Must be contained in a single paragraph."
},
"options": {
"type": "object",
"properties": {
"option_a": {
"type": "string",
"description": "The OPTION A of the question.",
},
"option_b": {
"type": "string",
"description": "The OPTION B of the question.",
},
"option_c": {
"type": "string",
"description": "The OPTION C of the question.",
},
"option_d": {
"type": "string",
"description": "The OPTION D of the question.",
},
},
"required": ["option_a", "option_b", "option_c", "option_d"]
},
"answer": {
"type": "string",
"description": "The single letter of the CORRECT OPTION of the question.",
"explanation": {
"type": "string",
"description": "The explanation about the quiz with up to 400 characters."
},
"imdb_url": {
"type": "string",
"description": "The IMDb URL link of the movie."
}
},
"required": ["question", "options", "answer", "explanation", "imdb_url"]
}
위의 스키마에서 각 항목에 포함된 description에는 해당 항목에 대한 설명문이 들어간다. 필수 요소는 아니지만, 여기에 입력한 내용은 GPT가 해당 데이터를 생성할 때 일종의 프롬프트로 간주하여 결과물에 반영하므로 간결하면서도 명료하게 써두는 것을 추천한다.
마지막 항목으로 위치한 required에는 위에서 정의한 데이터 스키마 가운데 필수적으로 생성되어야 할 항목들을 리스트 형태로 나열하도록 한다.
Chat Completion API 호출 코드 수정하기
이제 위에 작성한 스키마를 반영하여 Chat Completion API를 호출해보자. 앞서 생성한 JSON 스키마(quiz_data_schema)는 API 호출 구문의 functions 파라미터 안에 위치한 parameters 항목에 포함시켜야 한다. 수정한 호출 코드는 아래와 같다.
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
messages=[
{
"role": "system",
"content": "Suppose you are an examiner in the movie lecture class."
},
{
"role": "user",
"content": prompt
}
],
# Implement a function call with JSON output schema
functions=[{
"name": "get_new_quiz",
"description": "Get a new quiz with four options about the given movie. There's only one correct option.",
"parameters": quiz_data_schema
}],
# Define the function which needs to be called when the output has received
function_call={
"name": "get_new_quiz"
},
temperature=parameters["temperature"],
top_p=parameters["top_p"],
frequency_penalty=parameters["frequency_penalty"],
presence_penalty=parameters["presence_penalty"],
max_tokens=parameters["max_tokens"]
)
# return response["choices"][0]["message"]["content"].strip()
return response["choices"][0]["message"]["function_call"]["arguments"]
여기서는 functions와 function_call에 각각 get_new_quiz라는 함수를 사용자 측에서 실행하도록 지시하고 있다. 이에 따라 return 코드에 포함된 response 데이터 구조가 살짝 변화한 것에 주의하자. 우리가 받고자 하는 것은 위에서 지정한 get_new_quiz 함수 실행에 필요한 인자들, 즉 위에서 quiz_data_schema로 지정한 JSON 형태의 데이터이기 때문이다.
JSON 데이터 생성 결과물 확인하기
위와 같이 수정된 코드를 통해 만들어진 새 퀴즈 데이터의 생성 결과물은 다음과 같다. 의도한 대로 퀴즈에 필요한 모든 데이터 항목들이 지정된 JSON 형식에 맞춰 깔끔하게 정리되었다.
{
"question": "Who played the role of Satine in the movie 'Moulin Rouge!'?",
"options": {
"option_a": "Nicole Kidman",
"option_b": "Cameron Diaz",
"option_c": "Scarlett Johansson",
"option_d": "Kate Winslet"
},
"answer": "A",
"explanation": "'Moulin Rouge!' is a musical film released in 2001. The role of Satine, a courtesan and star performer at the Moulin Rouge, was played by Nicole Kidman. She received critical acclaim for her performance and was nominated for an Academy Award for Best Actress.",
"imdb_url": "https://www.imdb.com/title/tt0203009/"
}
위의 JSON 데이터가 포함된 응답 데이터(response) 전문은 다음과 같이 구성되어 있다. response["choices"][0]["finish_reason"]의 값이 function_call로 되어 있고, 그 아래의 response["choices"][0]["message"]에 포함된 function_call 항목에 JSON 데이터와 함수명이 포함되어 있음을 알 수 있다.
{
"choices": [
{
"finish_reason": "function_call",
"index": 0,
"message": {
"content": null,
"function_call": {
"arguments": ...,
"name": "get_new_quiz"
},
"role": "assistant"
}
}
],
"created": 1687940082,
"id": "chatcmpl-XXXXXXXXXXXXXXXXXXXXXXX",
"model": "gpt-3.5-turbo-0613",
"object": "chat.completion",
"usage": {
"prompt_tokens": 373,
"completion_tokens": 138,
"total_tokens": 511
}
}
GPT의 응답을 통해 요청받은 함수를 실행시키기
사용자의 백엔드 측에서는 위와 같은 응답 데이터에서 지정된 함수명(get_new_quiz)을 체크하여, 응답 수신 시점에 해당 함수가 자동으로 실행되도록 만들 수 있다. 이때 앞서 생성된 JSON 형태의 출력물을 함수의 인자로 넘기는 것도 가능하다. 아래는 이를 구현한 예시 코드다.
response_message = response["choices"][0]["message"]
# Check if function has called
if response_message.get("function_call"):
# Define variables based on the response message
function_to_run = response_msg["function_call"]["name"]
function_args = json.loads(response_msg["function_call"]["parameters"])
# Call the function with generated arguments
if function_to_run == "get_new_quiz":
get_new_quiz(
question=function_args.get("question"),
options=function_args.get("options"),
answer=function_args.get("answer"),
explanation=function_args.get("explanation"),
imdb_url=function_args.get("imdb_url")
)
else:
print(f"Error: function {function_to_run} does not exist.")
이러한 기능을 좀 더 응용한다면, GPT의 생성 데이터로 외부의 API를 호출하여 결과값을 받아낸 뒤 이를 다시 GPT로 넘겨서 자연어로 변환시키는 프로세스를 구성할 수도 있다. 이에 대해서는 OpenAI가 Cookbook을 통해 소개한 예시를 참고하도록 하자.
장단점 및 시사점
API 간 교신에 적합한 포맷의 데이터 생성
Function Calling은 GPT를 사용자의 백엔드 함수나 외부 API와 연동하기 쉽게 만들어준다는 명확한 장점을 가진다. 프롬프트에 양식을 하나하나 지정한 뒤 예시까지 보여줘야만 가능했던 JSON 데이터 출력이 이제는 OpenAI API에서의 파라미터 추가 만으로 간단히 이루어진다. "자연어로 JSON 데이터 얻기"라는 작업을 약간의 코드 만으로 자동화할 수 있게 된 것은 엔지니어 입장에서 무척 매력적인 부분이다.
더 짧은 프롬프트로 토큰 사용량 절약 가능
Instruction Prompting, Few-shots 등의 프롬프트 엔지니어링 기법 없이도 원하는 규격의 JSON 데이터를 얻을 수 있다. 이는 곧 프롬프팅에 필요한 토큰량의 감소, 즉 비용의 절감을 의미한다.
지난 글에서 소개한 KinoQuizAI 앱을 예시로 하여, Function Calling 도입 전후의 프롬프트 입력량을 비교해보았다. 결과는 아래 이미지와 같다. 극적인 차이를 실감할 수 있을 것이다.

할루시네이션에 의한 JSON 응답의 불안정성 존재
그러나 Function Calling 기능도 할루시네이션(hallucination)의 저주를 피해갈 수는 없었다. 아래는 실제로 GPT를 이용한 JSON 데이터 출력 실험 과정에서 발생한 잘못된 응답의 한 사례다.
{
"question": "Which actor played the role of Rick Blaine in the movie 'Casablanca'?",
"options": {
"option_a": "Humphrey Bogart",
"option_b": "Ingrid Bergman",
"option_c": "Claude Rains",
"option_d": "Paul Henreid"
},
"answer": "A",
"explanation": "'Casablanca' is a classic film released in 1942. The iconic character Rick Blaine was portrayed by Humphrey Bogart, who delivered a memorable performance in this romantic drama set during World War II. Bogart's portrayal of Rick has become one of his most famous roles and contributed to the enduring popularity of the movie.",
// IMDb URL for Casablanca (1942)
// https://www.imdb.com/title/tt0034583/
// I used imdb_url property here instead of url just to demonstrate that it can be any absolute URL.
imdb_url:"https://www.imdb.com/title/tt0034583/"
}
주석을 지원하지 않는 JSON 데이터에 뜬금없이 주석(//) 표기와 함께 불필요한 코멘터리가 붙었다. 게다가 imdb_url 항목의 이름에는 쌍따옴표(")가 빠져있다. 이런 데이터를 유효성 검사 없이 다른 API로 넘긴다면 각종 오류에 시달리게 될 것이다. 사용자 입장에서는 GPT가 생성한 내용의 진실성 뿐만 아니라 데이터 규격의 유효성 또한 검증해야 하는 것이다.
현재 Function Calling이 지원되는 gpt-4-0613과 gpt-3.5-turbo-0613 모델 기준으로는 아쉽게도 위와 같은 잘못된 응답의 빈도가 적지 않은 편이다. OpenAI 측의 점진적인 개선을 기대해 본다.