OpenAI API를 애플리케이션의 백엔드 데이터 에이전트로 활용한 KinoQuizAI 개발 후기
ChatGPT를 계기로 생성AI(Generative AI)는 대화형 에이전트나 컨텐츠 생성 모델로서 유용성이 입증된 상태다. 하지만 이것에 포함되어 있는 방대한 학습 정보 자체를 일종의 데이터 소스로 활용하는 방안은 없을까? 이 의문을 해소하기 위해 만든 KinoQuizAI 프로젝트의 개발 과정과 문제 해결 경험, 그리고 후기를 정리했다.

예전에 ChatGPT와 프롬프트 만으로 간단한 SNS 애플리케이션을 만들어 본 적이 있다. 이 경험에서 확신을 얻었다. 적절한 지시어 만으로 고도로 양식화 된 문법의 코드 생성까지 가능한 수준이라면, 학습된 데이터에서 내게 필요한 내용 만을 골라낸 뒤 일정한 규격으로 파싱하여 바로 얻어내는 일도 가능할 것이다. 자연어로 결과물을 내보내는 대화형 에이전트 대신, 데이터베이스에 바로 삽입할 수 있도록 전처리된 결과물을 뽑아내는 백엔드 데이터 에이전트 역할을 언어 모델에게 맡겨보는 것이다.

이 아이디어를 토대로 지난 4월에 KinoQuizAI라는 간단한 프로젝트를 만들었다. GPT 언어 모델이 생성한 영화 퀴즈를 풀고 점수를 얻는 웹 게임이다. ChatGPT와 같은 언어 모델 기반 서비스가 대화형 에이전트 뿐만 아니라 백엔드 기능 수행 도구로써도 유용할 것인가를 확인하는 것이 목적이었다. 결과는 기대 이상이었다. 이번 글에서는 KinoQuizAI의 개발 과정과 문제 해결 경험, 그리고 후기를 정리하고자 한다.

 seongjinme
seongjinme프로젝트 사전 기획 사항
소재 선택 : 영화퀴즈
GPT에 포함된 학습 데이터는 웹에 공개된 범용 정보들에 기반한다. 따라서 GPT에 학습된 정보를 백엔드 데이터 소스로 활용하려면, 공개된 데이터가 많아 학습량이 충분히 누적되었을 소재를 골라야 했다. 할루시네이션(hallucination)에 의한 거짓 응답의 가능성을 줄이려는 목적도 있었다. IMDb 등 널리 알려진 데이터 소스가 많은 영화는 이러한 조건에 부합하는 유용한 소재였다.
서비스 언어 선택 : 영문
ChatGPT 서비스의 근간이 되는 GPT 언어 모델에서 한국어 데이터 학습량은 영어 데이터에 비해 극히 적다. OpenAI가 공개한 데이터에 따르면, GPT-3 기준으로 전체 사전학습 데이터 가운데 한국어 데이터는 문서 단위로 0.019%, 단어 단위로 0.017%에 불과했다. 이대로는 한국어로 생성한 영화 콘텐츠의 품질을 보장하기 어렵다고 판단했다. OpenAI Playground에서 gpt-3.5-turbo 모델로 직접 실험한 결과도 예상과 다르지 않았다. 이러한 현실을 고려하여 KinoQuizAI는 처음부터 영문 서비스로 기획했다.
기술 스택 : Django, JS, Tailwind CSS, Supabase, GCP
이번에 내가 선택한 기술 스택은 다음과 같다.
- Backend : Python(Django)
- Frontend : JavaScript, Tailwind CSS, HTML
- DB, Storage : Supabase
- Infra : GCP App Engine
개발을 시작할 당시의 나는 하버드의 CS50 웹 개발 과정을 수강하고 있었다. 때문에 KinoQuizAI는 자연스럽게 내 졸업 프로젝트로 선택되었다. 해당 교육 과정의 원칙상 Django 프레임워크와 JavaScript를 반드시 써야 했다. 다만 화면 구현의 편의성을 위해 Tailwind CSS를 추가로 사용했다. 덕분에 스케치 노트 한 장 없이도 원하는 화면을 빠르게 만들 수 있었다.
Supabase는 Firebase의 오픈소스형 대안 서비스로 알려져 있다. 프롬프트 파일 관리와 콘텐츠 DB 구축을 위해 선택했다. 처음엔 DB용 인스턴스를 따로 구성하려 했지만, 적절한 솔루션을 이용하여 불필요한 공수를 줄이고 아이디어를 빠르게 구현하는 일 또한 엔지니어에게 필요한 덕목이라고 보았다. Supabase의 경우 Python 지원이 오로지 사용자 커뮤니티에 의존하여 이루어지고 있으며, 공식 매뉴얼과 실제 적용 방법이 불일치하는 문제가 남아있다. 그러나 무료 티어에서도 PostgreSQL DB와 스토리지를 간편하게 쓸 수 있다는 명확한 강점이 있다.
배포처로는 과거에 실무 경험이 있었던 GCP의 App Engine을 선택했다. 원래 이용하려 했던 Vercel이 무료 티어에서는 Function Timeout이 최대 10초로 제한하는 것을 확인 후 계획을 바꾸었다. 현재 OpenAI API로부터 응답 데이터를 받기까지는 대개 5-15초 이상이 소요된다. OpenAI API 사용을 전제한 환경에서는 빠듯한 제약이다. 무료 티어를 제공하는 다른 배포처들 역시 크고 작은 부분에서 내게 필요한 조건을 충족하지 못했다. 결국 돈 내고 편히 가자는 마음으로 GCP를 선택했다. 2023년 4월 당시 GCP는 신규 가입자에게 첫 3개월 동안 $300+100 상당의 쿠폰을 주었는데, 이것도 큰 매력 요소였다.
애플리케이션 동작 구성
OpenAI API 통신 시퀀스 구성
KinoQuizAI 앱의 핵심 동작은 클라이언트 - 서버 - OpenAI API 간의 통신 시퀀스에서 비롯된다. 머릿속이 백지 상태였던 프로젝트 시작 당시, macOS에 기본으로 포함된 Freeform 앱으로 이 시퀀스의 동작 구조를 상상하여 대강 그려 보았다. 내용은 아래와 같다. (이같은 그림 형식을 시퀀스 다이어그램(Sequence diagram)이라 부른다는 걸 최근에야 알았다.)
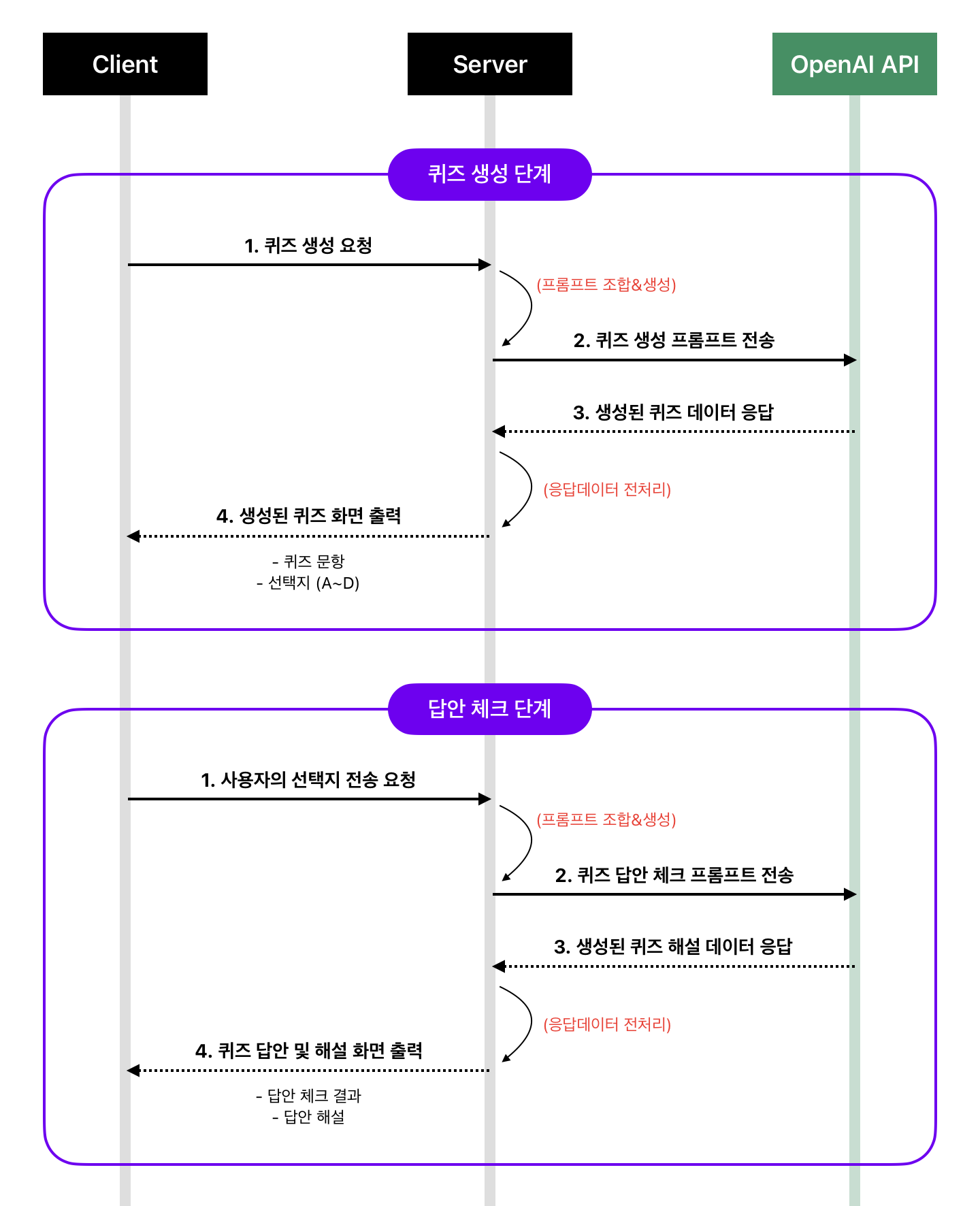
- 클라이언트에서 사용자가 서버로 퀴즈 생성을 요청한다.
- 서버는 퀴즈 생성에 필요한 프롬프트를 조합하여 OpenAI API로 전송한다.
- 서버는 OpenAI API를 통해 생성된 퀴즈 데이터를 전송 받는다.
- 서버는 받은 데이터를 전처리 후 클라이언트로 전송한다.
- 퀴즈 답안 체크 상황에서도 똑같은 방법으로 1-4번 단계를 반복한다.
이렇게 구성한 시퀀스로 개발에 돌입하자, 기획 단계에서 놓쳤던 문제점이 나타나기 시작했다.
- 매번 퀴즈를 받아 풀 때마다 OpenAI API와의 교신이 두 차례나 오가야 한다. 응답 지연 현상이 현저한 OpenAI 측과의 교신 횟수 증가는 사용자 입장에서 더 많은 불편으로 이어진다.
- GPT는 언어 모델이다. 사실이나 현상에 대한 판단을 수행하는 도구가 아니다. 현재의 기획안은 GPT에게 퀴즈 채점이라는 원리적으로 불가능한 역할을 강제한다. 따라서 채점 결과물의 품질이 보장될 수 없다.
위의 두 가지 문제를 해소하기 위해서는 전체적인 시퀀스 구조를 훨씬 단순화해야 했다. 서비스 제공자 입장에서 통제 불가능한 영역을 최소화하는 것이다. 수정한 결과는 다음과 같다.
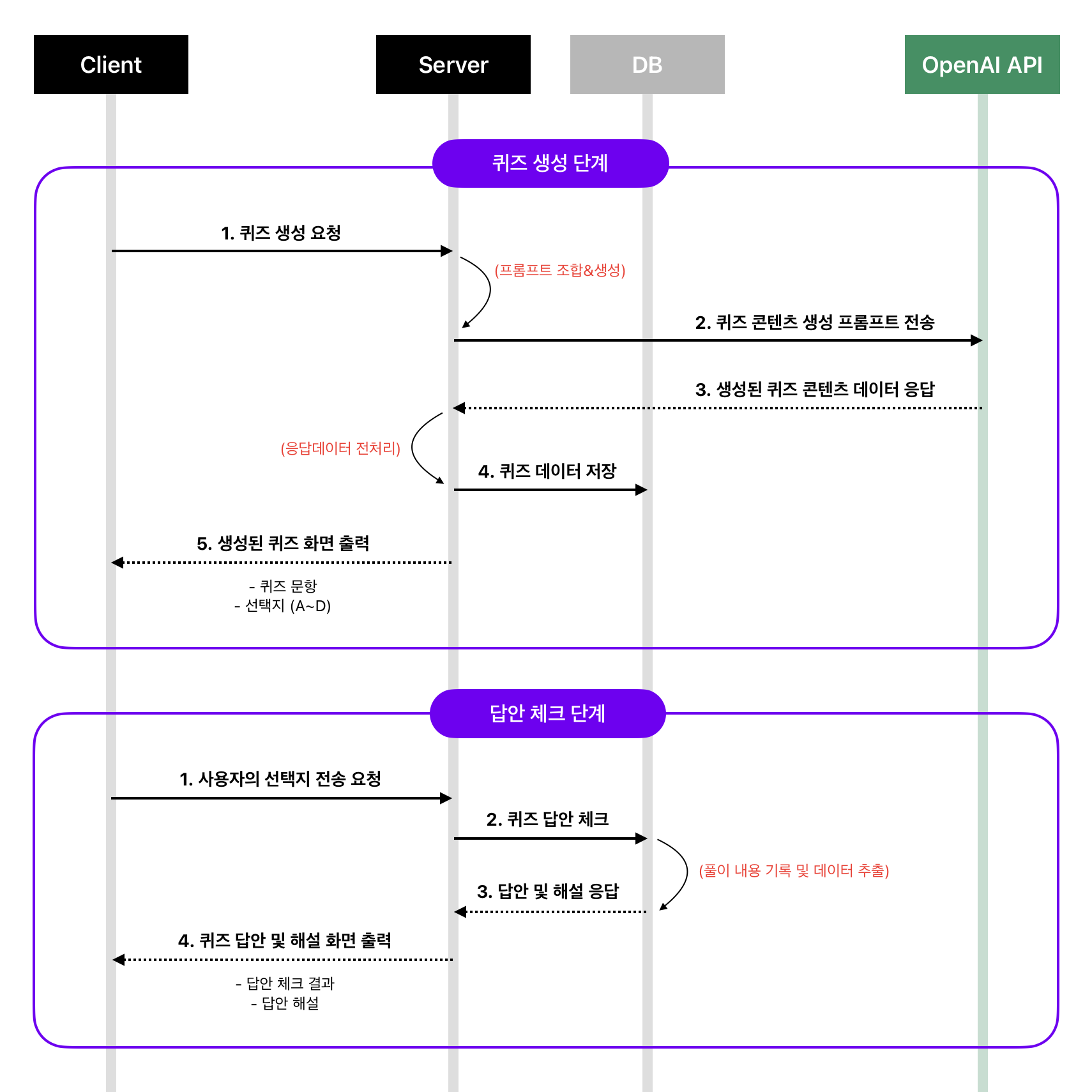
- 클라이언트에서 사용자가 서버로 퀴즈 생성을 요청한다.
- 서버는 새로운 퀴즈 콘텐츠(문항, 선택지, 정답, 해설, IMDb URL 등)를 생성하기 위한 프롬프트를 조합하여 OpenAI API로 전송한다.
- 서버는 OpenAI API를 통해 생성된 퀴즈 데이터를 전송 받는다.
- 서버는 받은 데이터를 전처리하여 DB에 저장한다.
- 서버는 DB에 저장 완료된 퀴즈 데이터를 클라이언트로 전송한다.
- 이후 퀴즈 답안 체크 단계는 클라이언트 - 서버 간 통신으로만 이루어진다.
이렇게 하니 OpenAI API와의 교신을 회당 한 번으로 줄일 수 있었다. 사용자 응답에 대한 지연 시간도 줄이고, 비용도 줄어들 뿐만 아니라 처음에 의도했던 사용자 경험도 매끄럽게 유지된다. 구현도 더욱 간단해졌다.
그런데 사용자가 퀴즈를 요청할 때마다 매번 콘텐츠를 생성받도록 하는 방식은 아무래도 비효율적이다. 다른 사용자에 의해 이미 생성되어 DB에 저장된 퀴즈를 신규 사용자에게 우선 제공하도록 하면 훨씬 효율적이지 않을까? 그래서 다음과 같이 시퀀스를 재설계했다.
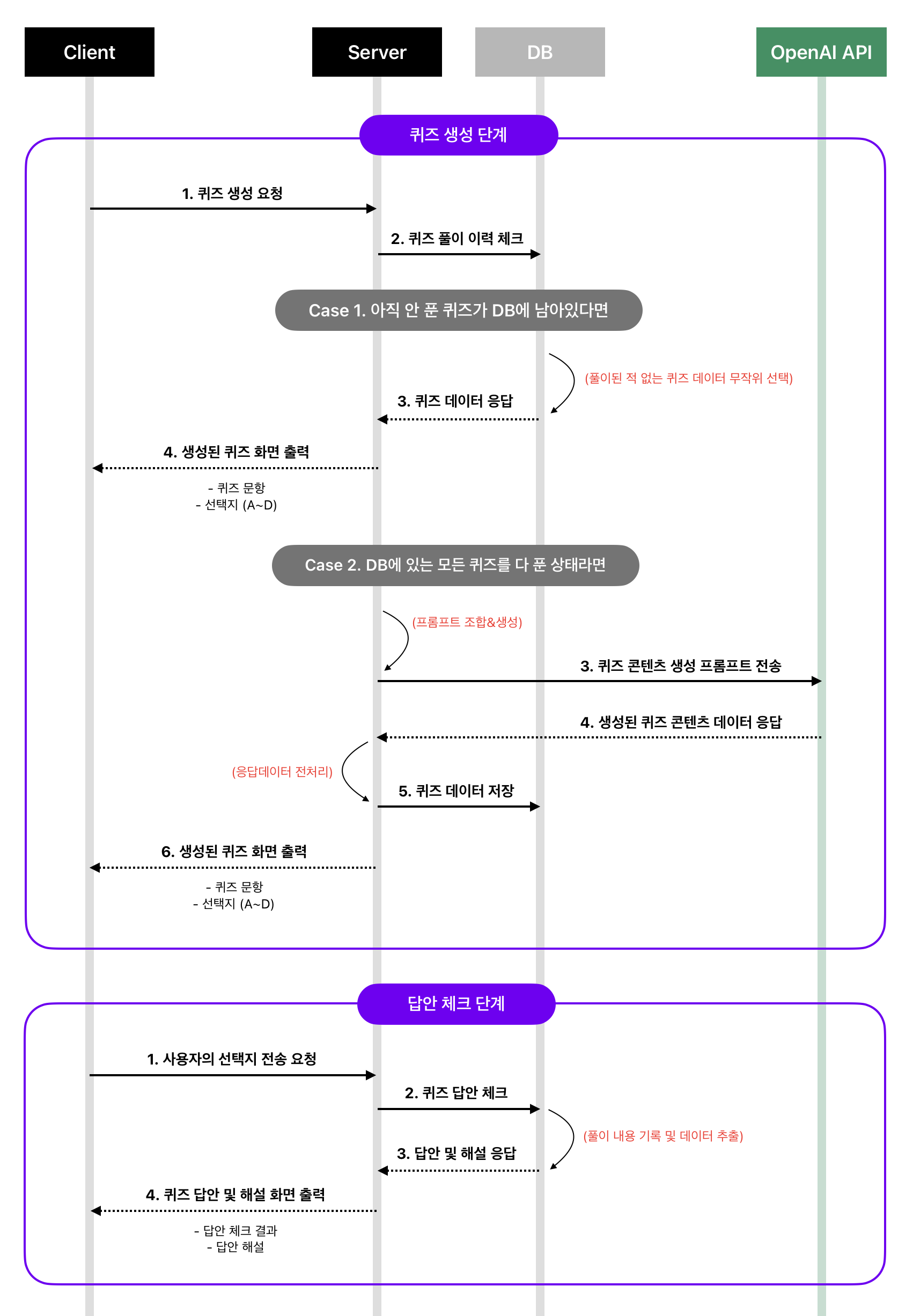
- 클라이언트에서 사용자가 서버로 퀴즈 생성을 요청한다.
- 서버는 DB에 저장된 사용자의 퀴즈 풀이 이력을 체크한다.
- 아직 풀이되지 않은 문제들이 DB에 남아있다면, 그들 중 하나를 무작위로 뽑아 클라이언트로 전송한다.
- 이 사용자가 DB에 저장된 모든 문제를 풀이한 상태라면, 새로운 퀴즈 콘텐츠(문항, 선택지, 정답, 해설, IMDb URL 등)를 생성하기 위한 프롬프트를 조합하여 OpenAI API로 전송한다. 서버는 OpenAI API를 통해 생성된 퀴즈 데이터를 전송 받은 뒤, 데이터를 전처리하여 DB에 저장 후 클라이언트로 전송한다.
- 이후 퀴즈 답안 체크 단계는 클라이언트 - 서버 간의 통신으로만 이루어진다.
이렇게 재설계한 시퀀스 구성을 본 프로젝트에 최종적으로 반영했다. 결과는 만족스러웠다. 서비스 오픈 후 첫 일주일 동안 약 200여명의 사용자들로부터 총 510건의 문제 풀이가 이루어졌다. 기존에 생성된 퀴즈 콘텐츠를 신규 사용자에게 우선적으로 제공하도록 한 결과, 오직 106개의 퀴즈 콘텐츠 만으로 이 모든 참여가 원활하게 이루어졌다. 퀴즈 풀이 간 딜레이를 줄이는 등 사용자 경험을 크게 개선하면서도 외부(유료) API 호출량 또한 약 80% 가량 절감할 수 있었다.
데이터 테이블 구성
시퀀스 구성 못지 않게 중요한 일이 데이터 저장 구조를 정하는 것이다. 과거 SQL 자격증을 공부하던 시절의 기억을 살려 ERD(Entity Relationship Diagram)을 먼저 그린 후에 Django 모델 생성 및 마이그레이션 작업을 진행했다.
ERD를 그릴 때엔 dbdiagram.io 서비스를 이용했다. 이 서비스는 데이터베이스 마크업 언어인 DBML로 DB 스키마와 구조를 마치 코딩하듯이 시각화할 수 있게 해준다. 아래 이미지는 2023년 5월 현재 운영 중인 버전의 데이터 테이블 구성을 나타낸 다이어그램이다.
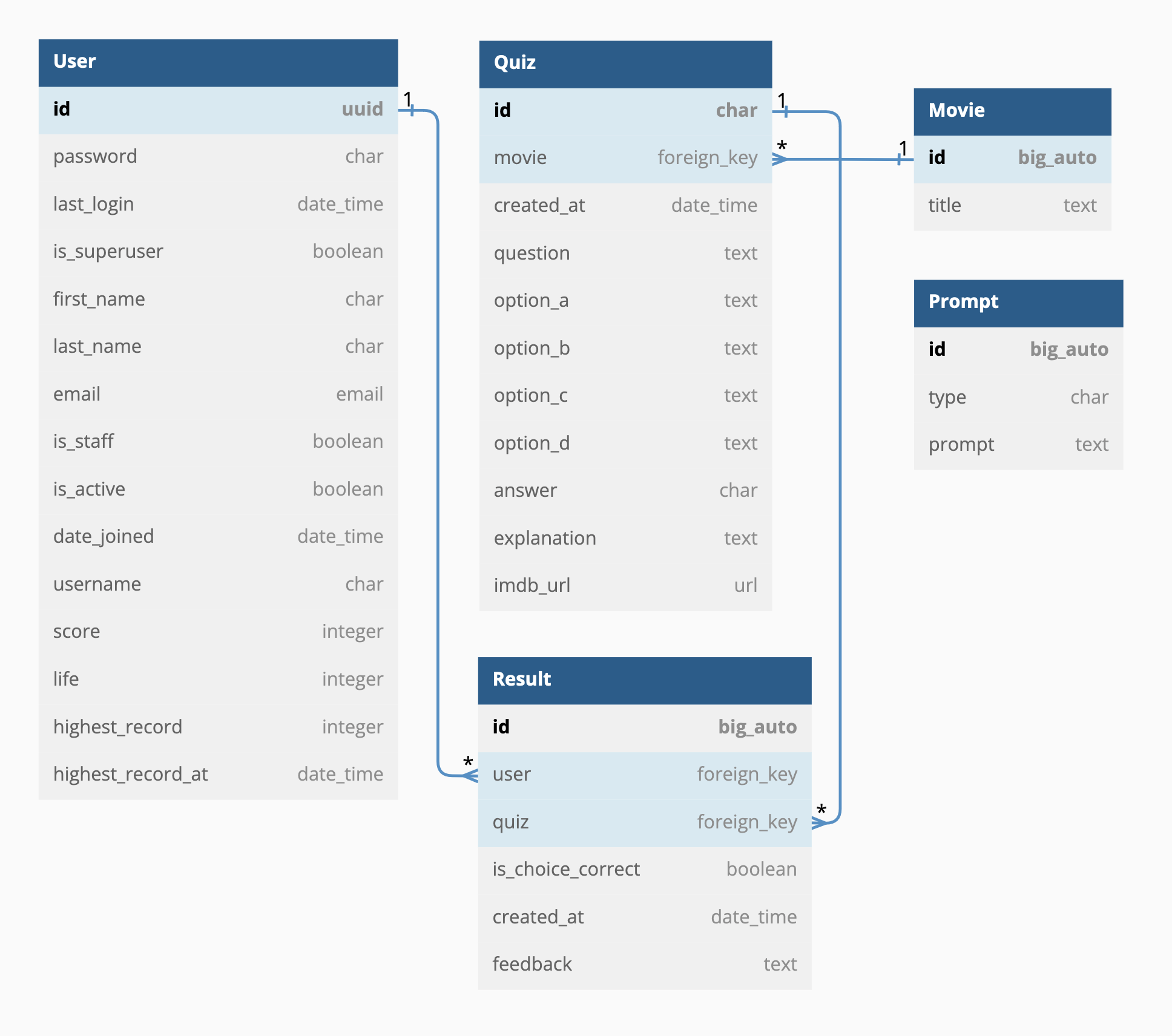
여기서 Quiz 테이블의 역할이 가장 중요하다. 이 앱이 정상적으로 동작하려면, OpenAI API를 통해 생성된 콘텐츠가 파싱 및 전처리 단계를 거쳐 이 테이블의 question, option, answer, explanation, imdb_url 필드에 각각 차곡차곡 쌓여야 한다. 이 프로세스가 오류 없이 돌아가려면 생성 결과물의 꾸준한 일관성이 보장되어야 한다. 이 일관성을 만들어내기 위해선 결국 프롬프트 엔지니어링에 공을 들여야 했다.
프롬프트 엔지니어링
프롬프트의 품질이 응답의 품질을 결정한다. 단순히 좌우하는 정도가 아닌 하늘과 땅 수준의 차이를 만든다. KinoQuizAI 앱은 구상부터 배포까지 총 20일이 걸렸는데, 그 중 절반인 열흘을 오직 프롬프트 엔지니어링에만 썼다.
이번 프로젝트에 적용한 프롬프팅 기법들을 아래에 소개한다. 모두 데이터베이스에 바로 삽입 가능하도록 가공된 콘텐츠를 안정적으로 생성받기 위해 적용한 내용들이다. 이에 대해서는 OpenAI의 응용 AI 연구부문 수석(Head of OpenAI's Applied AI Research)인 Lilian Weng의 글과 The Stanford AI Lab Blog에 올라온 In-context Learning 소개글로부터 큰 도움을 얻었음을 밝힌다.
Instruction Prompting
Instruction Prompting은 언어 모델이 결과물을 생성할 때 따라야 할 지시사항을 직접적으로 전달하는 프롬프팅 기법이다. 언어 모델로 하여금 사용자의 의도를 잘 읽어내어 지시된 내용을 따르도록 유도하는 가장 기초적인 방법이다. 이에 대해서 Lilian Weng은 자신의 프롬프트 엔지니어링 소개 글에서 다음과 같이 유의사항을 남긴 바 있다.
When interacting with instruction models, we should describe the task requirement in details, trying to be specific and precise and avoiding say “not do something” but rather specify what to do.
- 작업에 필요한 요구 사항들을 세분화하여 자세히 설명한다.
- 지시 내용은 구체적이고 명확해야 한다.
- "무엇을 하지 말라"고 하기보단 "무엇을 해야 하는지"를 구체적으로 명시한다.
KinoQuizAI 앱이 올바르게 동작하려면, OpenAI API로부터 전달 받은 생성물이 지정된 양식에 따라 정확히 파싱된 상태여야 한다. 그래야 생성된 퀴즈 콘텐츠를 DB에 적재한 뒤 사용자들에게 서비스할 수 있다. 이를 위해서는 프롬프트에 (1) 어떤 콘텐츠를 생성해야 하는가, (2) 이 콘텐츠를 어떤 양식으로 출력해야 하는가에 대한 지시사항이 모두 자세하게 포함되어야 한다.
우선 콘텐츠 생성을 위한 프롬프트 내용 예시를 소개하면 다음과 같다. 이와 같은 방법으로 퀴즈 콘텐츠로서 갖추어야 할 양식과 조건을 하나하나 나열했다.
Create a single movie quiz with four options. The quiz must follow conditions described below:
- The question must have four options: (A), (B), (C), (D) for answers.
- Only one option must be correct.
- Do not make up the content of correct option with false information.
- ...
다음으로는 생성된 콘텐츠의 출력 양식을 지정한다. 이 내용을 프롬프트로 작성한 예시는 아래과 같다.
According to the conditions above, generate each element of the quiz. Follow the instructions below.
- There must be eight elements: question, option A, option B, option C, option D, right option, explanation, and IMDb URL.
- Include a single line-break(`\n`) at the end of each element.
- At the first line, ...
- At the second line, ...
이와 같은 방식으로 여러 실험 끝에 퀴즈 생성용 프롬프트를 완성했다. 실제 운영 환경에서는 예시 데이터와 공백을 포함하여 약 2,800자 분량의 프롬프트가 쓰였다. 여기엔 9개의 콘텐츠 생성 조건과 12개의 출력 조건이 포함되었다.
In-context Learning
In-context Learning은 프롬프트에 작업 지시문(task description)과 더불어 하나 이상의 입출력 예시(few-shot)를 함께 포함시키는 프롬프팅 기법으로, GPT-3 논문에 소개된 것처럼 Few-shot Learning으로도 알려져 있다. 작업을 지시할 때 사용자가 원하는 올바른 형태의 입출력 예시를 언어 모델에게 인지시킨 뒤, 프롬프트의 최하단에 예시와 유사한 입력 문구를 더함으로써 실제 결과물 또한 그러한 양식을 따르도록 유도하는 것이다. OpenAI 공식 문서의 "Quickstart"에 포함된 "Add some examples"의 내용이 이 기법을 활용한 대표적인 예시다.

다만 이 프로젝트에서는 여러 실험 끝에 하나의 예시만 프롬프트에 포함시키는 One-shot 기법을 사용했다. 이유는 다음과 같다.
- 여러 개의 예시를 주었을 때 마지막 순서의 예시 내용과 거의 동일한 퀴즈 생성이 반복되었다.
- 때때로 주어진 예시의 개수만큼 여러 개의 퀴즈가 연달아 생성되는 문제가 발생했다.
- 예시가 많아질 수록 토큰 소모도 늘어난다. 이는 비용의 문제로 이어진다.
퀴즈의 유형, 내용, 규칙에 대해서는 이미 앞선 프롬프트로 상세하게 정해두었으므로, 여기서는 결과물의 출력 양식을 언어 모델에게 인지시키는 용도로만 예시를 활용하기로 했다. 프롬프트 하단에 덧붙인 예시 내용은 다음과 같다. 그 결과, 예시와 똑같은 양식대로 깨끗하게 정리된 퀴즈 데이터를 얻을 수 있었다.
...
- Follow the exact format of the example below. Do not include additional line-break between the elements.
- After the end line of this prompt, start printing your question.
[Question]
In the movie "Inception", what is the name of the device that allows people to enter and share dreams?
(A) The Dreamcatcher
(B) The PASIV Device
(C) The Mind Explorer
(D) The Dream Weaver
B
The PASIV (Portable Automated Somnacin IntraVenous) Device is a briefcase-like machine used by Cobb and his team to enter and share dreams. It's designed to administer a sedative called somnacin, which puts all users into a synchronized sleep state, allowing them to connect with one another in a shared dream world.
https://www.imdb.com/title/tt1375666/
[Question]
실제 운영 환경에서는 위와 같은 예시를 총 12개까지 만들어 DB의 Prompt 테이블에 수록하고, 새 퀴즈를 생성할 때마다 이들 중 하나를 무작위로 골라 프롬프트에 추가하도록 해두었다. 똑같은 내용의 예시가 반복되어 유사한 유형의 퀴즈 생성이 되풀이될 가능성을 줄이기 위해서다.
Parameter tuning
퀴즈를 만들 때엔 창의력과 엄밀성이 함께 필요하다. 모든 퀴즈가 똑같이 주인공 이름만 묻는 식이어선 곤란하다. 애써 풀어낸 퀴즈가 엉뚱한 선택지를 정답으로 소개하는 상황도 피해야 한다. 문항과 선택지에는 다채로운 소재와 흥미 요소가 권장되고, 답안과 해설에 대해서는 내용의 정확성이 우선해야 한다.
서로 다른 두 가지 특성이 퀴즈 생성 과정에 반영되도록 만드는 일은 쉽지 않았다. 하지만 결과물의 품질을 높이려면 반드시 해내야 했다. 이럴 때 필요한 것이 바로 파라미터 튜닝(Parameter tuning)이다. OpenAI API에 프롬프트와 함께 보낼 수 있는 temperature, top_p, frequency_penalty, presence_penalty 등의 파라미터 값을 통해 GPT의 생성 결과물에 어느 정도의 창의성(혹은 획일성)을 부여할지 조정하는 것이다. 각 파라미터의 용도는 OpenAI API 공식문서에서 확인하도록 하자.
지난한 실험 끝에 KinoQuizAI 앱을 위한 파라미터값을 다음과 같이 정했다. temperature와 top_p 값을 모두 높게 가져가면서 보다 창의적인 문장을 구사하게 했고, frequency_penalty와 presence_penalty 또한 높게 설정하여 동일한 소재로 엇비슷한 내용이 반복되지 않도록 유도했다.
parameters = {
"temperature": 1.15,
"top_p": 0.7,
"frequency_penalty": 1,
"presence_penalty": 0.85,
"max_tokens": 2048
}
이렇게 파라미터 튜닝을 마치자 놀라운 일이 벌어졌다. 이전에는 주연 배우나 감독 이름만 반복적으로 묻는 퀴즈만 만들어졌었다. 그러나 튜닝 이후에는 영화 속 대사, 설정, 줄거리 등을 소재로 다양한 유형의 퀴즈가 생성되기 시작했다. 작은 디테일이 거대한 품질 차이로 이어진다는 격언을 실감한 순간이었다.
프롬프트 엔지니어링 결과
이렇게 프롬프트 엔지니어링을 거치자 신규 콘텐츠 생성과 데이터 파싱, 수신, 전처리 및 DB 삽입 과정에 이르는 데이터 프로세싱이 매끄럽게 이어졌다. 서버 측에서는 OpenAI API와 교신한 뒤 전송받은 데이터를 검증한 뒤 바로 DB에 넣고 클라이언트로 전달하는 로직만 수행하면 되었다. ChatGPT와 같은 언어 모델 서비스를 백엔드 데이터 에이전트로 활용하는 아이디어가 성공적으로 구현된 것이다.
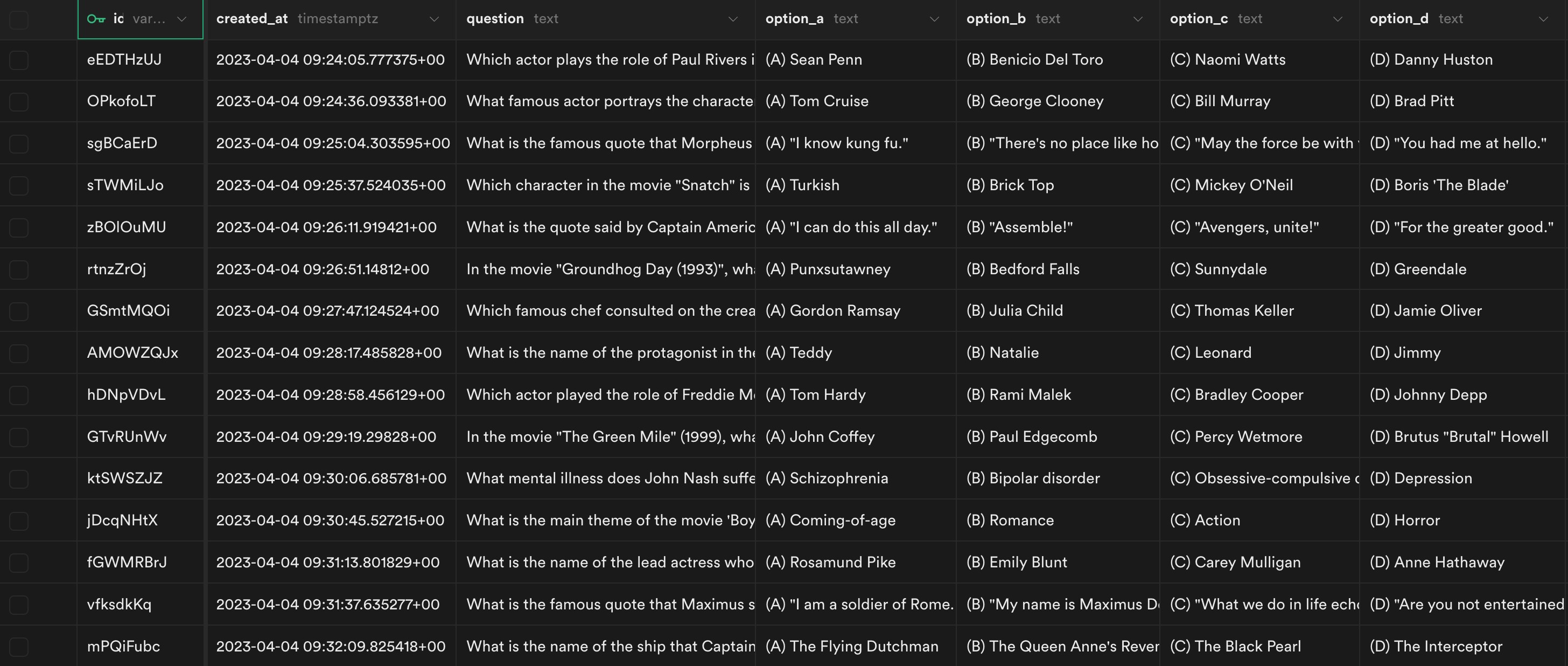
문제 해결 및 개선 경험
퀴즈 소재가 특정 영화에 편중되는 문제 해결하기
이렇게 만들어진 퀴즈 생성 시퀀스를 테스트하던 도중 예상치 못한 문제를 마주했다. 생성된 퀴즈의 소재가 극소수의 유명 영화들에 한정되고 있었다. <대부 Godfather>, <다크 나이트 The Dark Knight>, <인셉션 Inception>, <쇼생크 탈출 The Shawshank Redemption>을 다루는 엇비슷한 퀴즈가 반복적으로 만들어졌다. 살펴보니 이들은 모두 IMDb에서 사용자 별점수가 최상위권이라는 공통점이 있었다.
앞서 소개한 대로, GPT의 학습에 쓰인 데이터는 웹에 공개된 범용 정보들이다. 인터넷에서 자주 거론된 영화일 수록 학습된 데이터 양도 많을 것이고, 그렇지 못한 영화는 참고할 데이터 자체가 적기에 학습량도 부족할 것이다. 이러한 정보량의 격차가 임의의 영화 하나를 골라서 퀴즈를 만들 것이라는 프롬프트의 결과물 양상에도 영향을 미친 것이다.
나는 KinoQuizAI 앱이 세계적으로 널리 알려진, 평단과 대중의 높은 평가를 얻은 다양한 영화들을 골고루 다루길 원했다. 따라서 프롬프트의 첫 문구를 {영화}에 대한 퀴즈를 만들 것이라는 내용으로 수정하고, {영화} 부분에 랜덤하게 삽입시킬 영화 목록을 구성해서 DB에 미리 저장해두기로 했다.
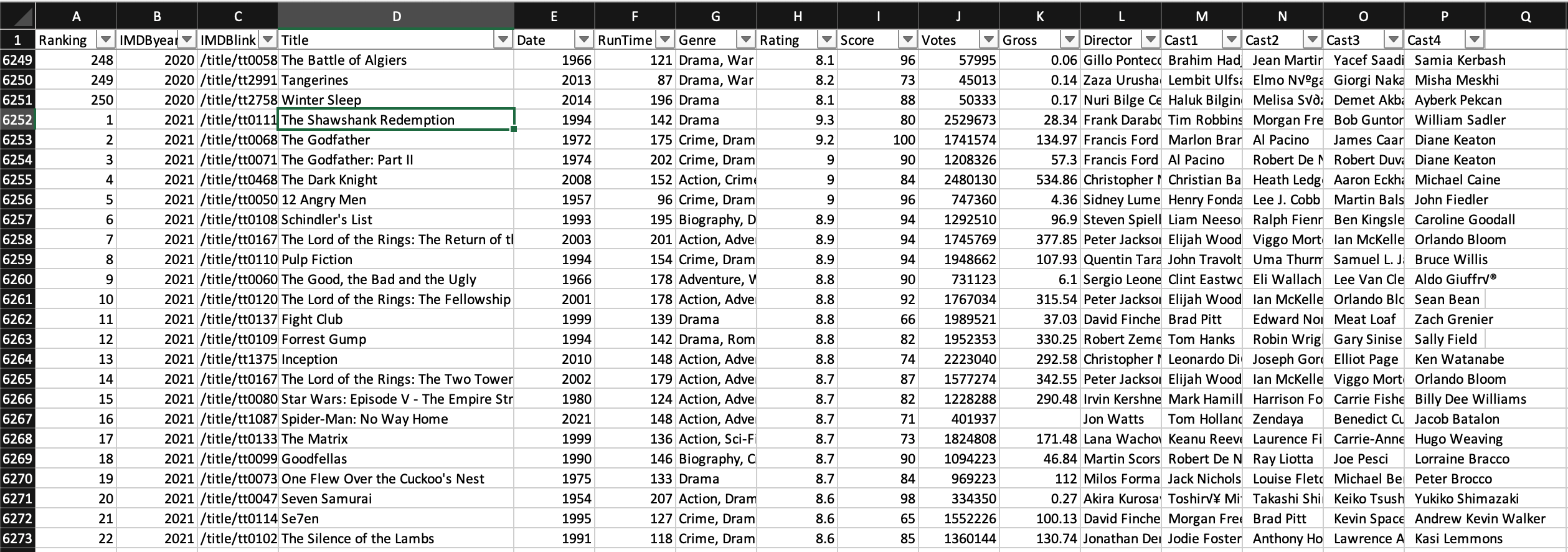
영화 목록을 선별하는 작업은 엑셀로 간단히 진행했다. 1996년부터 2021년까지 IMDb Top 250 Movie 리스트를 뽑은 뒤, 20만 개 이상의 사용자 별점을 획득한 상위 300개를 선별했다. 이렇게 선별한 영화 목록을 DB에 quiz_movie 테이블로 올리고, 퀴즈를 매번 생성할 때 각 영화에 부여된 id 값이 Foreign Key 값으로 따라붙도록 수정했다.
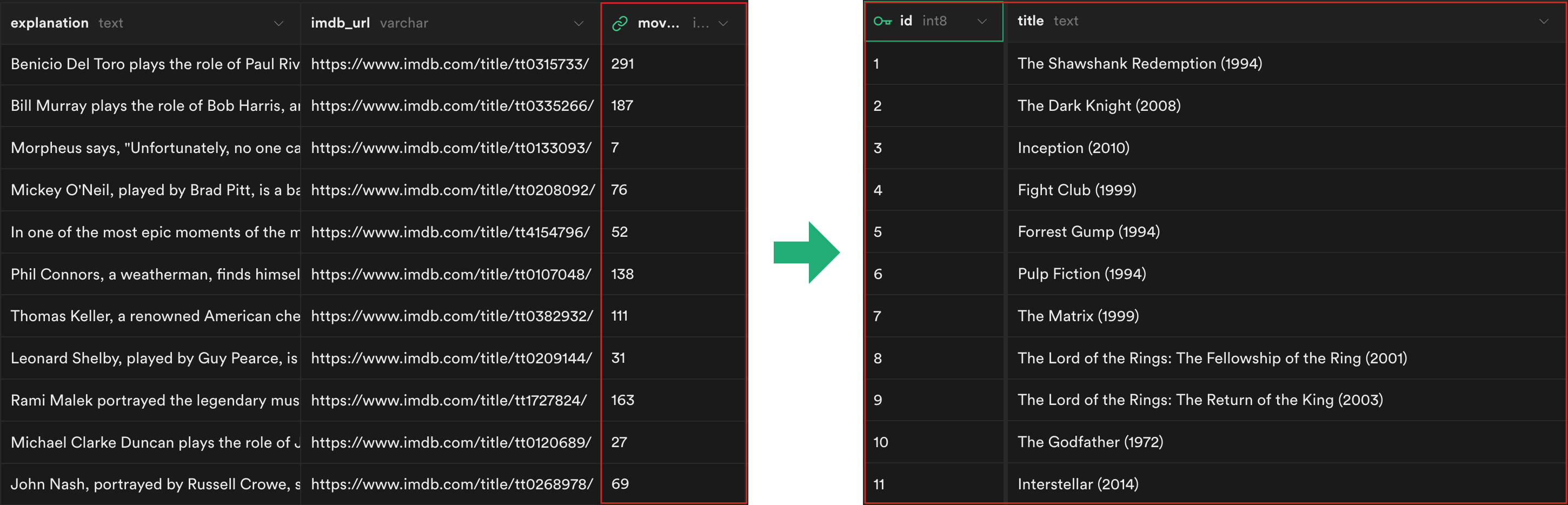
그 결과, KinoQuizAI 앱은 매번 새롭게 주어지는 영화 제목에 맞춰 퀴즈 생성을 올바르게 해냈다. 훨씬 다양한 영화들을 소재로 퀴즈를 만들게 된 만큼, 콘텐츠의 다양성과 깊이도 한층 늘어나게 되었다.
퀴즈가 생성될 때마다 정답이 (A)로 고정되는 문제 해결하기
생성 데이터가 누적되면서 이전에는 보이지 않았던 또다른 문제가 드러났다. 프롬프트에 4개의 선택지 중 임의의 하나를 정답으로 만들 것이라는 조건이 명시되었는데도, 실제로 생성된 퀴즈들 중 약 70%의 정답이 (A)로 고정되는 현상을 보였다. 즉, GPT 언어 모델은 여러 선택지를 가진 퀴즈를 생성할 때 가장 앞선 순서의 선택지를 정답으로 두고 내용을 채워넣는 경향을 보이고 있었다.

어느 한 가지 선택지로만 쭈욱 찍었는데 그게 다 정답이 되는 퀴즈 앱을 좋아할 사람은 없을 것이다. 이를 해결하기 위해 처음에는 프롬프트 엔지니어링을 시도했으나, 반복된 실험에도 별다른 효과를 보지 못했다.
결국 이 문제는 고민 끝에 퀴즈가 사용자에게 노출될 때마다 선택지를 뒤섞는 방법으로 해결했다. 서버 측에서 선택지 항목들을 프론트로 전송할 때마다 순서를 섞도록 하고, 프론트 측의 각 선택지에 해당하는 radio input의 value 값에는 해당 선택지의 원래 답안 기호(A, B, C, D)를 삽입하여 채점 과정에서 서버쪽 DB 내용과 비교 가능하도록 처리했다.
앱의 주요 로직이 포함된 views.py 파일에는 퀴즈를 생성한 후 클라이언트로 전송하는 get_quiz() 함수가 포함되어 있다. 이 함수의 리턴 코드는 원래 다음과 같았다.
...
return JsonResponse({
"quiz": {
"quiz_id": quiz.id,
"question": quiz.question,
"option_a": quiz.option_a,
"option_b": quiz.option_b,
"option_c": quiz.option_c,
"option_d": quiz.option_d
}
}, status=200)
위의 코드 내용을 아래와 같이 수정했다. 선택지 항목들을 무작위로 섞는 과정에서는 secrets 모듈에 포함된 randbelow를 사용했다. 각 퀴즈에 랜덤한 난수 ID를 붙이기 위해 secrets 모듈의 choice를 사용하고 있었기에, 편의상 같은 모듈에 포함된 난수 생성 함수를 쓰고자 했다. 파이썬의 문자열 슬라이싱 기능 또한 이 작업에 큰 도움이 되었다.
...
# Shuffle the order of options to make user experiences more dynamic
quiz_options = [quiz.option_a, quiz.option_b, quiz.option_c, quiz.option_d]
quiz_option_a = quiz_options.pop(randbelow(len(quiz_options)))
quiz_option_b = quiz_options.pop(randbelow(len(quiz_options)))
quiz_option_c = quiz_options.pop(randbelow(len(quiz_options)))
quiz_option_d = quiz_options.pop()
# Considering shuffled order of options,
# remove marks((A), (B), etc) from each option label before sending to the front-end.
# Additionally, provide the original option values to fill values in the radio input form
# which will be used to validate the user's choice.
return JsonResponse({
"quiz": {
"quiz_id": quiz.id,
"question": quiz.question,
"option_a": quiz_option_a[4:],
"option_b": quiz_option_b[4:],
"option_c": quiz_option_c[4:],
"option_d": quiz_option_d[4:],
"option_values": [quiz_option_a[1], quiz_option_b[1], quiz_option_c[1], quiz_option_d[1]]
}
}, status=200)
이렇게 수정하자 퀴즈가 생성될 때마다 정답이 (A)로 고정되는 문제가 해결되었다. 각각의 사용자가 같은 문제를 풀더라도 서로 다른 선택지 순서를 갖게 되므로 더욱 다이나믹한 사용자 경험이 만들어지는 효과도 얻을 수 있었다.
퀴즈 풀이 단계에서 목숨 기능 추가하기
더 많은 영화를 소재로 다루고, 매번 선택지의 순서도 바뀌게 되면서 퀴즈 풀이의 난이도 또한 덩달아 올라가게 되었다. 이런 여건에서 단 한 번의 오답이 게임 종료로 이어지는 설정은 사용자에게 너무 가혹해 보였다. 이때 마침 박제권님께서 만드신 퀴즈와(QuizWa) 웹 게임을 알게 됐다. 관련하여 "목숨 3개가 생겨서 아이들이 좋아했다"는 피드백을 본 후, 위의 게임에서 '목숨'을 하트 아이콘으로 표현한 디자인을 참고하여 KinoQuizAI에도 목숨 기능을 곧바로 추가했다.
우선 DB쪽 User 모델에 IntegerField로 기본값을 3으로 갖는 life 필드를 추가하고, 사용자가 게임을 새로 시작할 때마다 life 필드값을 3으로 초기화하는 코드를 추가했다. 사용자의 퀴즈 풀이 결과를 검증하는 get_result() 함수에는 오답일 경우 사용자의 life를 1 감소시킨 뒤, 해당 시점에서의 life 잔여값을 체크하여 게임 지속 여부를 판별하는 코드를 아래와 같이 추가했다.
# If user's choice was wrong, reduce user's life by 1
if not is_user_choice_correct:
user.life -= 1
user.save()
# Check whether user's remaining life
game_continue = True if user.life > 0 else False
...
return JsonResponse({
"quiz_result": {
"is_user_choice_correct": is_user_choice_correct,
"answer": quiz.answer,
"explanation": quiz.explanation,
"imdb_url": quiz.imdb_url
},
"user_status": {
"life": user.life,
"score": score,
"game_continue": game_continue,
"highest_record": highest_record,
"is_new_record": is_new_record
}
}, status=200)
이렇게 하여 JSON 포맷으로 전송된 user_status.life 값은 프론트에서 잔여 목숨을 표기하는 용도로 쓰고, user_status.game_continue 값은 게임 종료 여부를 판별하여 퀴즈 화면 하단의 버튼을 변경하는 용도로 사용했다.
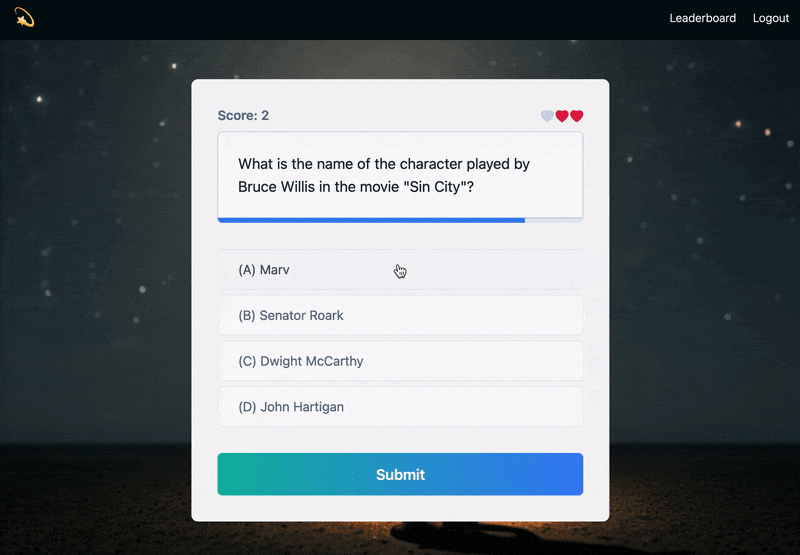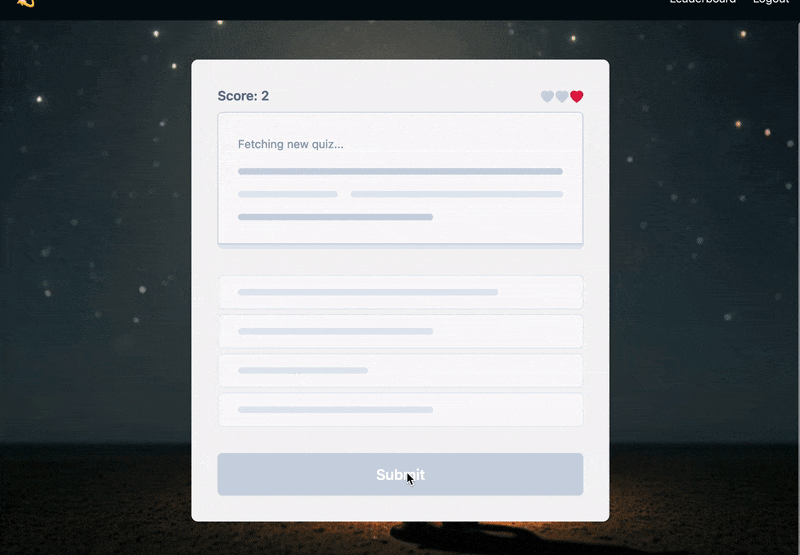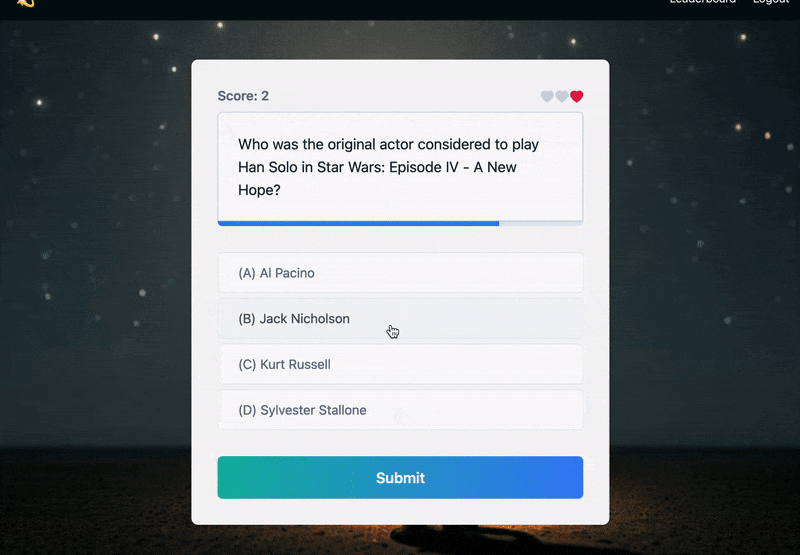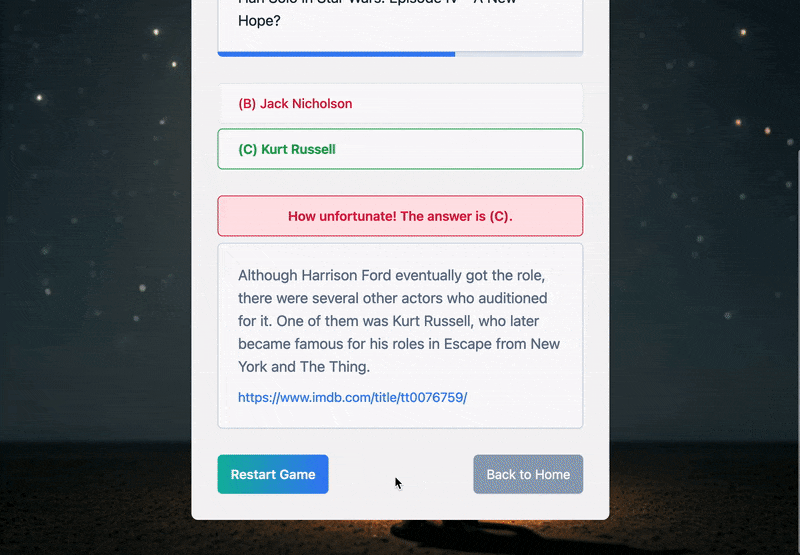
이처럼 목숨 기능을 추가한 덕분에 퀴즈 게임에 대한 진입 장벽을 낮추면서 재도전을 자연스럽게 유도하는 사용자 경험을 더할 수 있었다.
프로젝트를 통해 배운 것
세상에는 이미 GPT와 같은 언어 모델을 정보 종합 및 요약 솔루션의 용도로 결합시킨 상용 서비스가 여럿 존재한다. 이런 서비스들에 비하면 KinoQuizAI는 여가 목적의 작은 개인 프로젝트에 불과하다. 그러나 언어 모델을 데이터 에이전트로 활용함으로써 백엔드 영역에서의 서버 역할을 단순화 하면서도 다채로운 내용의 콘텐츠 생성과 데이터 축적을 동시에 구현해낸 점에서 개인적으로 큰 뿌듯함을 느꼈다.
다만 서비스를 이용하는 고객의 관점에서는 아쉬운 점도 남았다. 엔지니어의 입장에서 이 앱은 언어 모델에 학습된 데이터를 기반으로 안정적인 콘텐츠 생성 및 저장 솔루션을 만들어 냈다는 의의가 있다. 그러나 사용자 입장에서 이 앱은 그동안 많이 보아왔던 텍스트 기반 퀴즈 앱의 일종일 뿐이다. ChatGPT나 Bing Chat을 통해 흔하게 보아 왔던, 인공지능이 생성한 텍스트 특유의 예측불가성과 스트림 형태로 결과물이 중계되는 실시간성 등의 재미 요소가 이 프로젝트에선 배제되어 있다.
또한 지속적인 프롬프트 엔지니어링을 거쳤음에도 불구하고, 생성된 콘텐츠에 거짓 내용이 포함되는 경우를 완전히 제거할 수는 없었다. 아래는 KinoQuizAI 앱에서 106번째로 생성된 퀴즈 내용의 일부다.
In "Blade Runner 2049", what is the name of the company that created replicants?
(A) Wallace Corporation
(B) Tyrell Corporation
(C) Weyland-Yutani Corporation
(D) Waystar Royco
The correct answer is (B), Tyrell Corporation. In the original "Blade Runner" movie, replicants were created by the Tyrell Corporation. In "Blade Runner 2049", a new type of replicant has been developed by the Wallace Corporation, but they are still based on the original designs from Tyrell.
이 퀴즈의 실제 정답은 (A)다. 그런데 아래의 해설 문구 중 첫 문장에서는 (B)를 정답으로 소개하고 있다. 엉뚱하게도 그 다음 문장부터는 다시 (A)가 정답일 수밖에 없는 이유를 올바르게 해설하고 있다. 이처럼 거짓을 사실처럼 오도하거나 둘을 혼재시키는 할루시네이션(hallucination)이 106개 퀴즈 중 9개에서 발생하였다.
각종 파라미터 튜닝과 프롬프팅 기술이 더해지더라도 언어 모델 자체의 특성상 거짓 응답의 가능성은 필연적으로 발생한다. GPT를 도입한 각종 서비스들 또한 이러한 문제에 직면하고 있거나, 혹은 해결 중일 것이다. 언젠가 기회가 된다면 그 노하우를 익히고 싶다.